QwQ-32b 私有化部署
QwQ-32b 介绍
2025年3月6日,千问团队推出了 QwQ-32B,在一系列权威基准测试中,千问QwQ-32B 模型表现异常出色,几乎完全超越了OpenAI-o1-mini,比肩最强开源推理模型DeepSeek-R1:

如何在深度视觉AI平台使用 QwQ-32b
1. 首次使用
① 下载 深度视觉 AI 平台 安装包:https://dlcv.com.cn,完成安装;
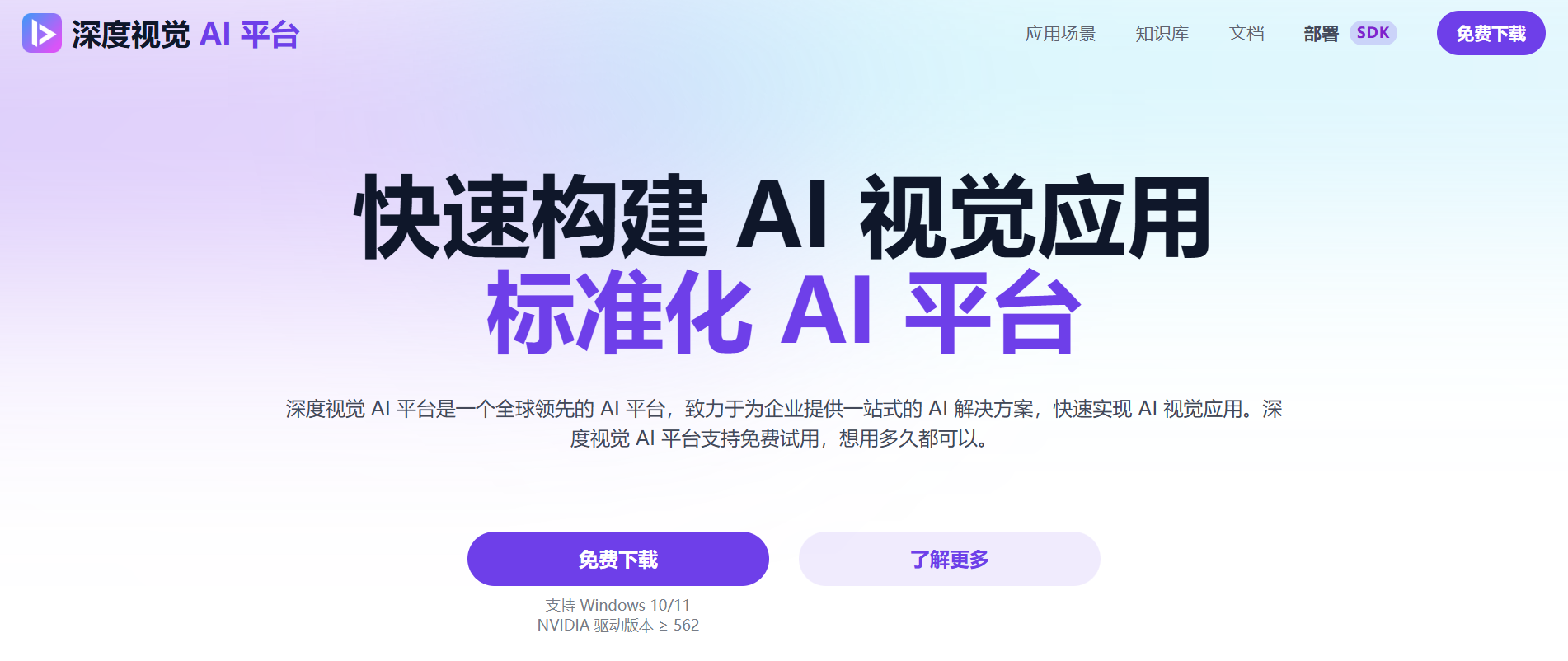
② 选择 QwQ-32b 模型,然后点击一键安装即可:

③加载好模型之后,就可以在 Open WebUI 中使用了:
2. 以前使用过
①下载模型
如果你之前已经安装过其他模型,那么你需要先切换到 QwQ-32b 模型,点击下载模型:
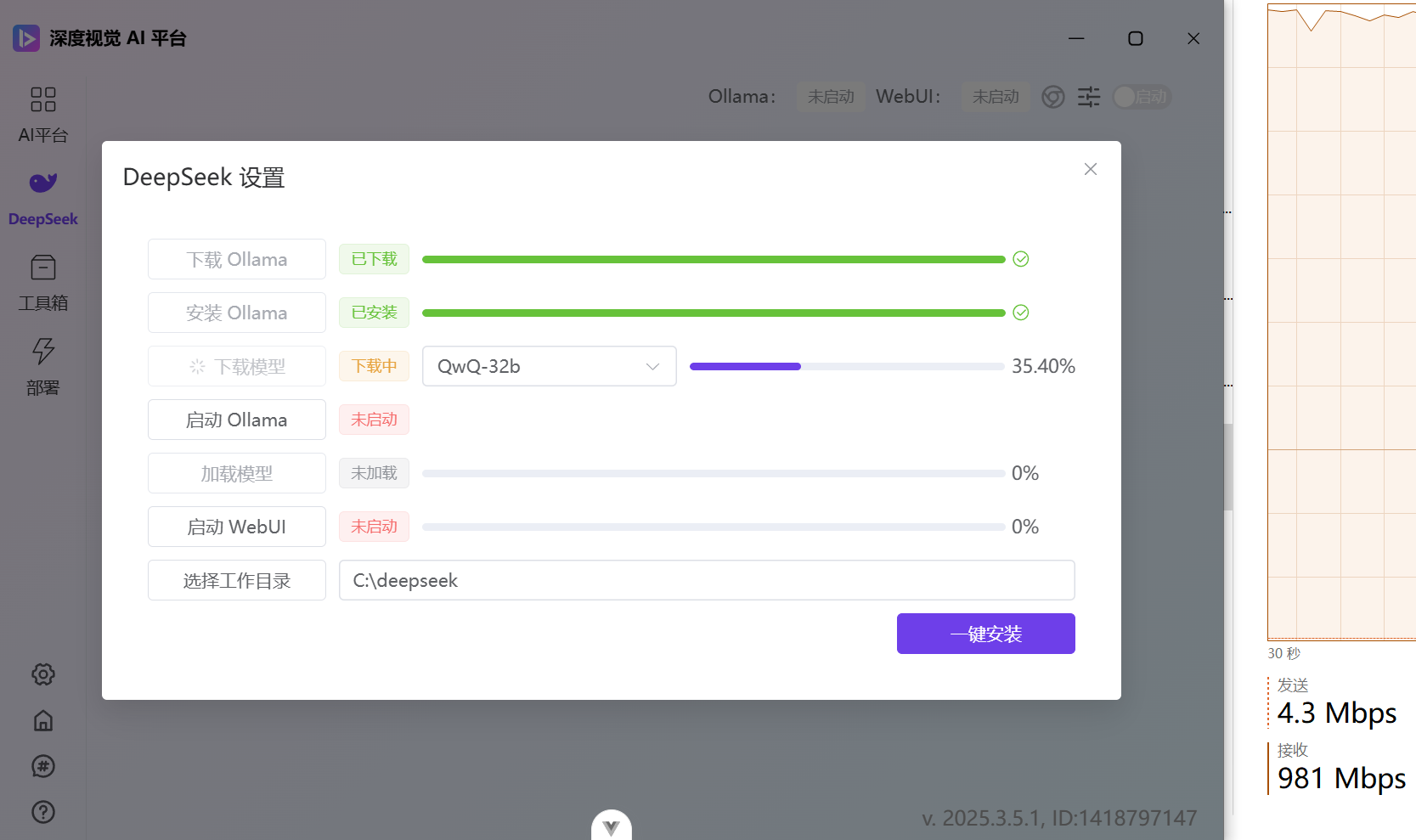
②加载模型
下载完成之后,点击加载模型:
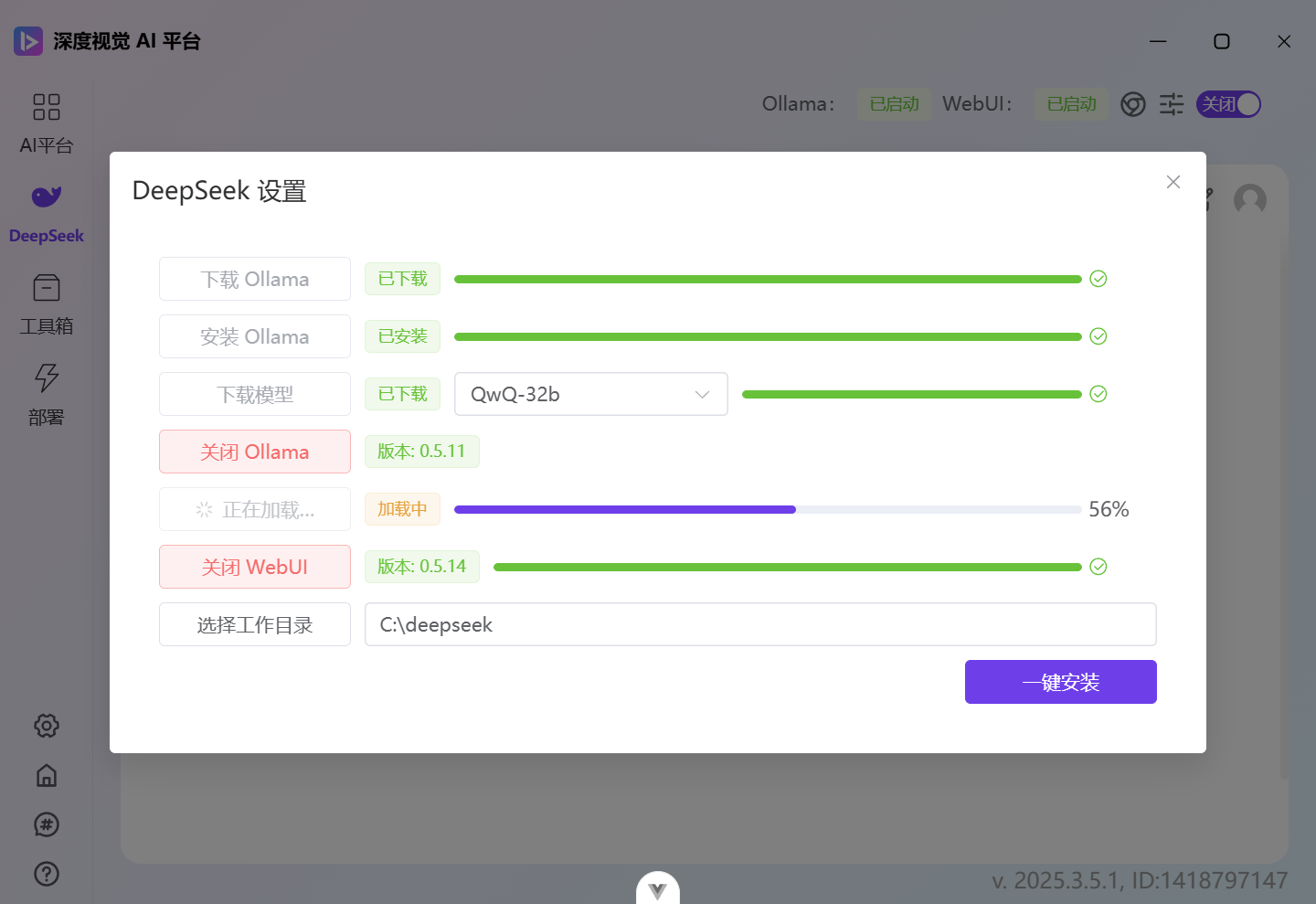
③加载好模型之后,就可以在 Open WebUI 中使用了:
对比测试
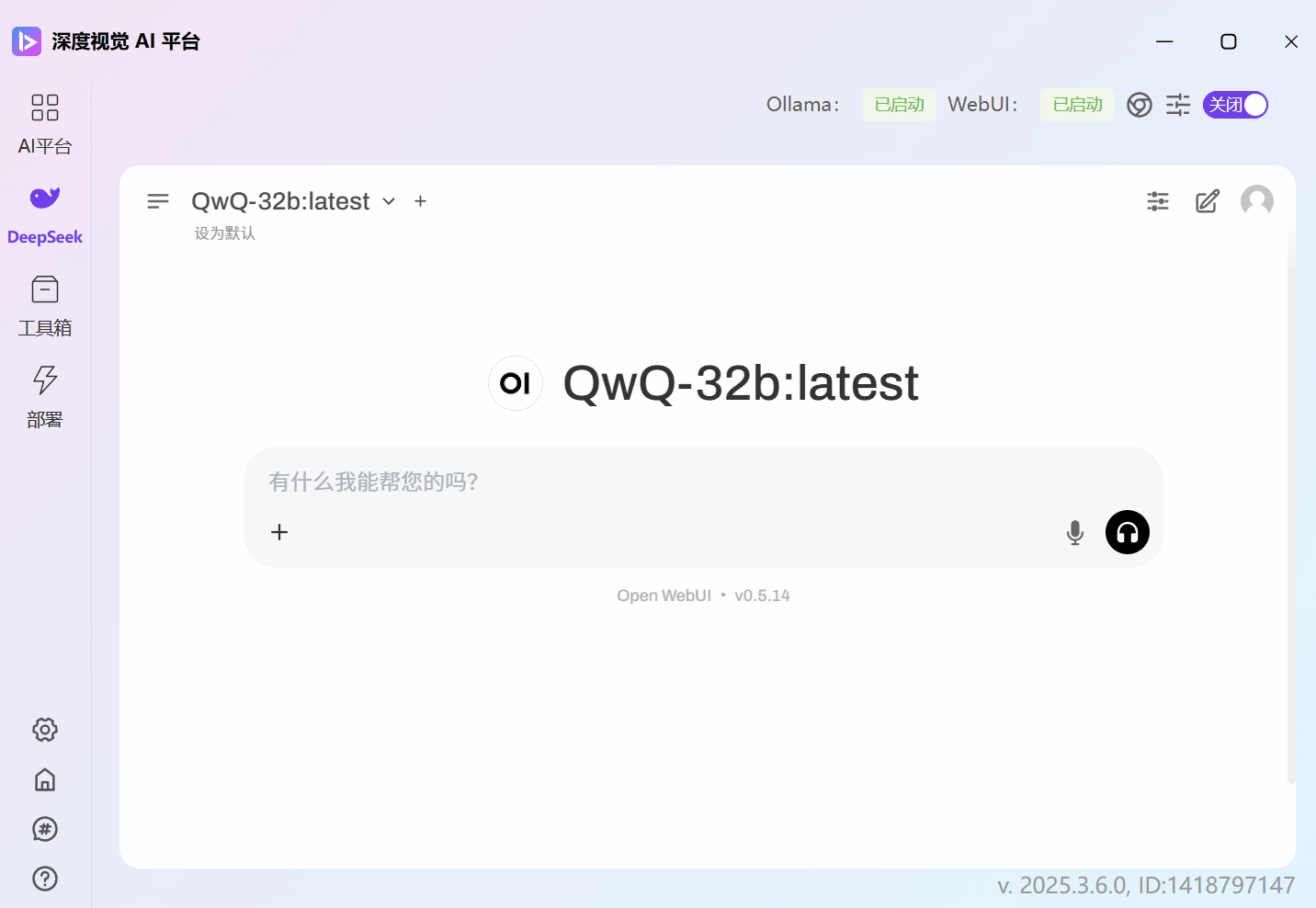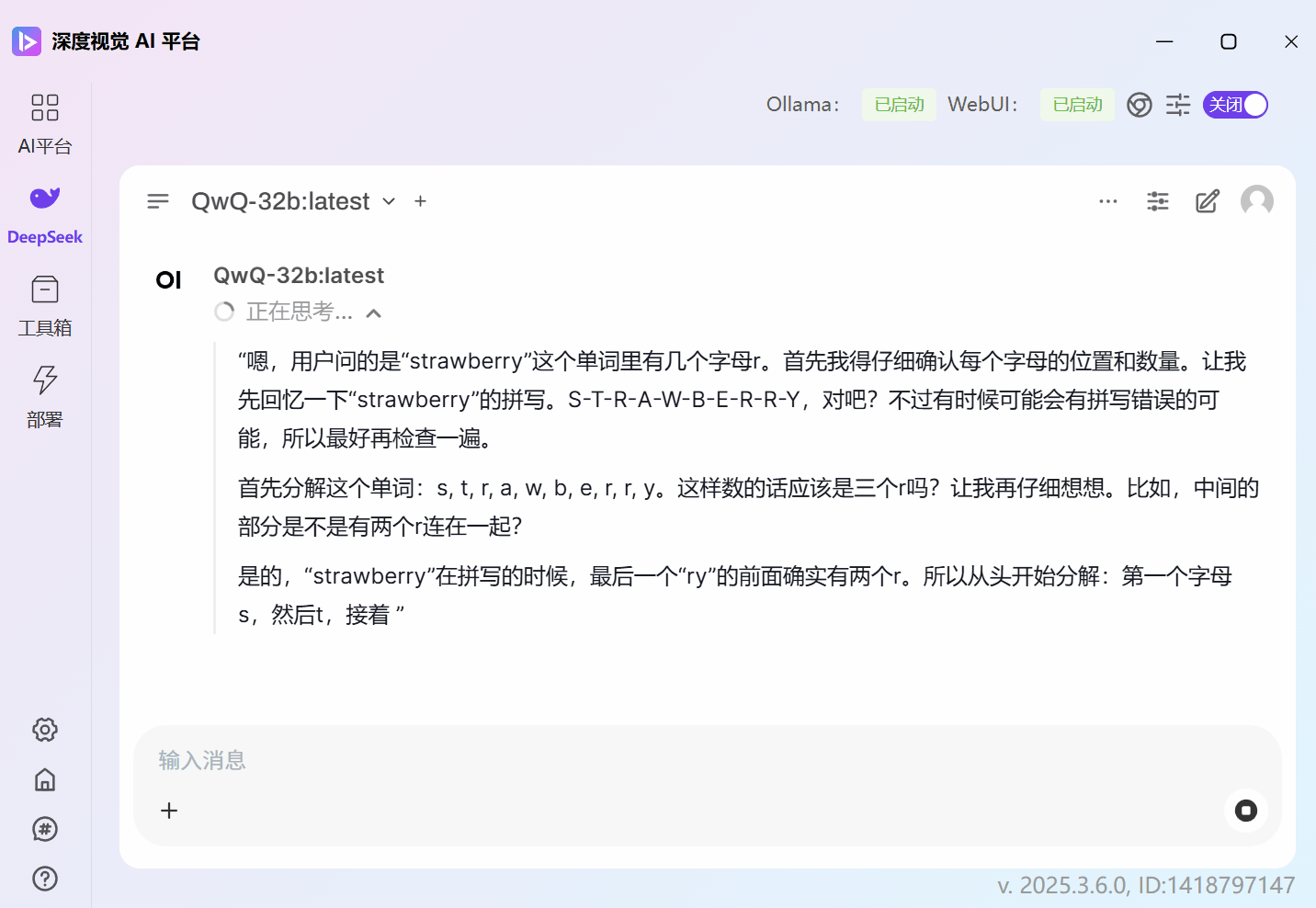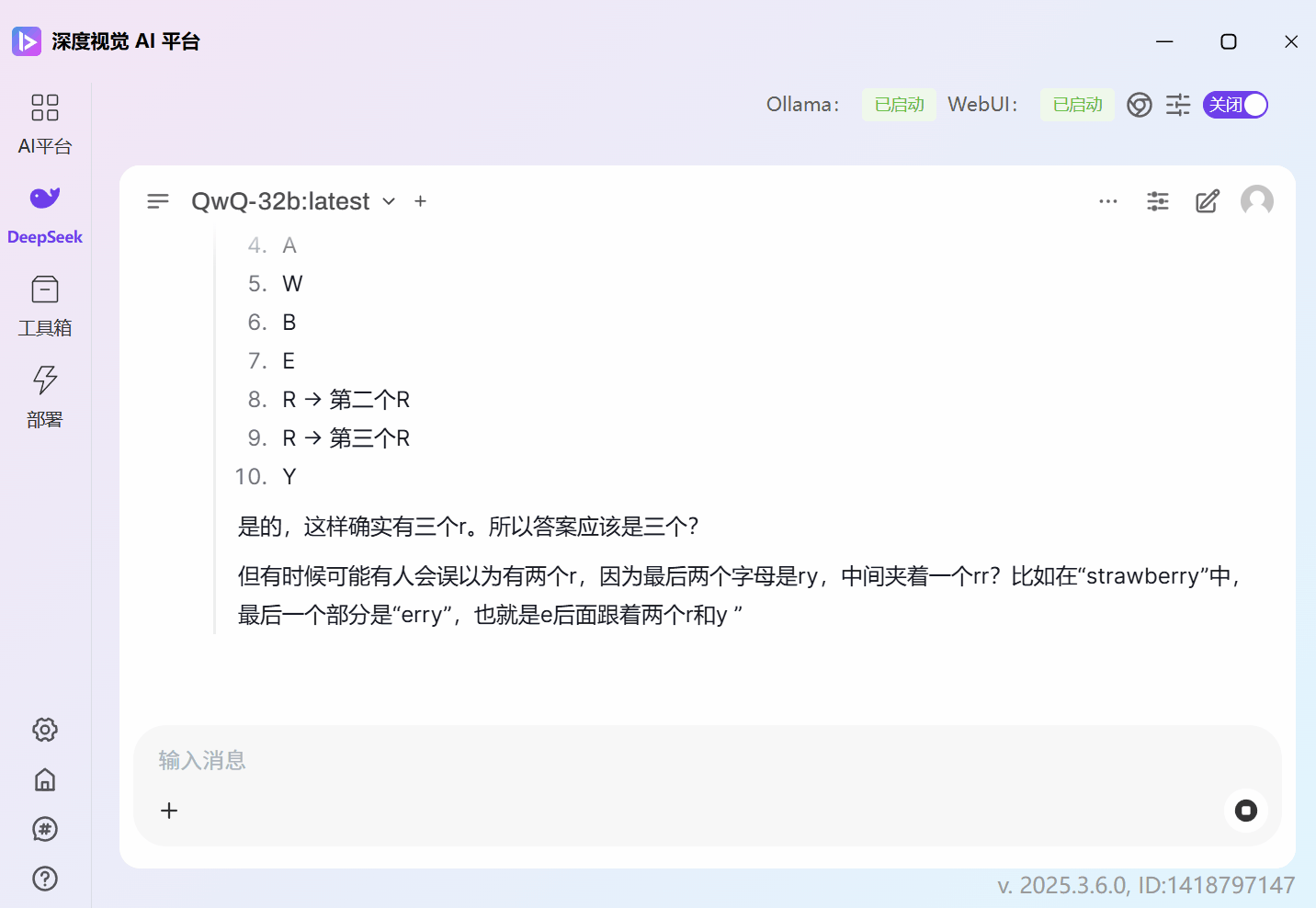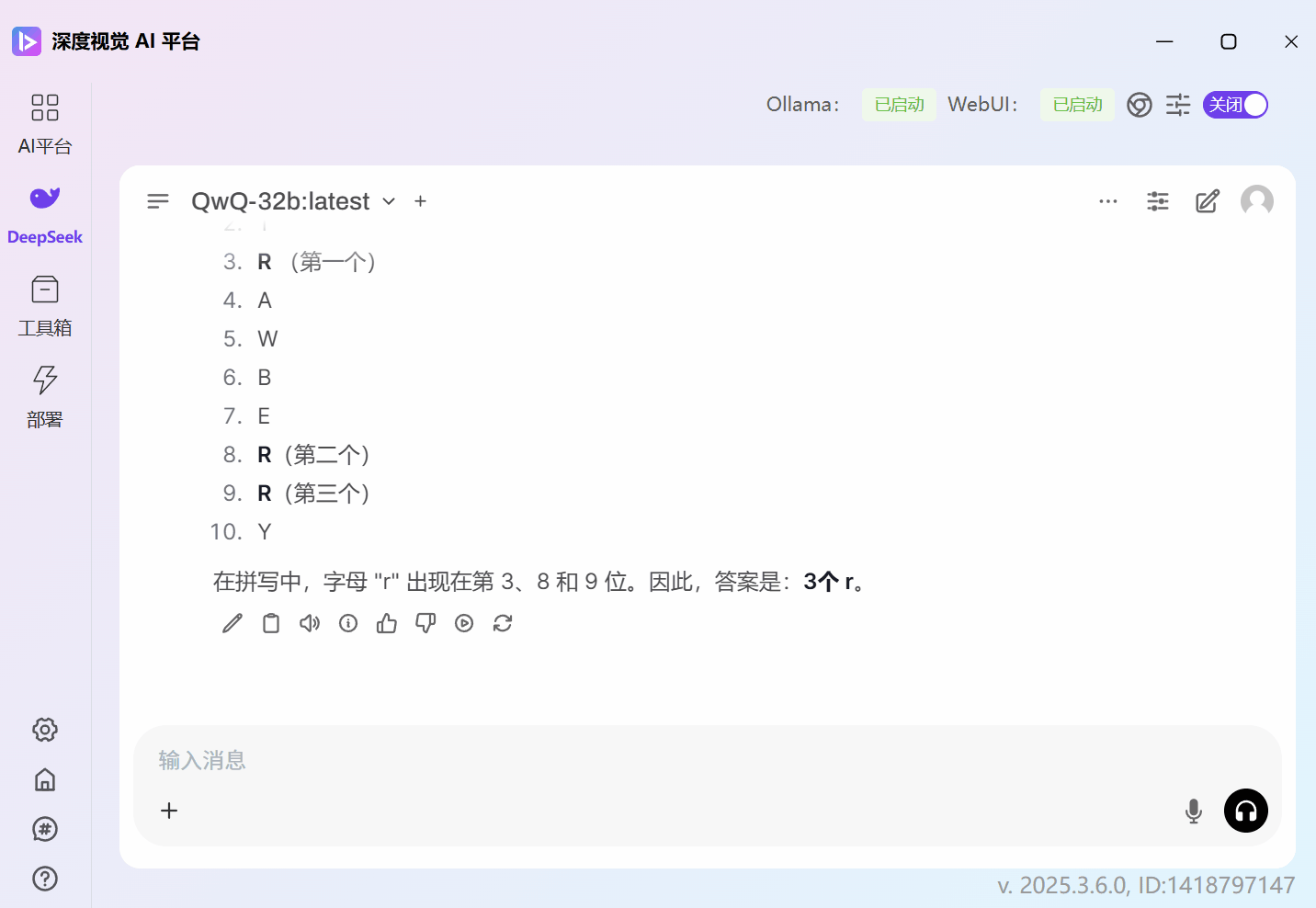
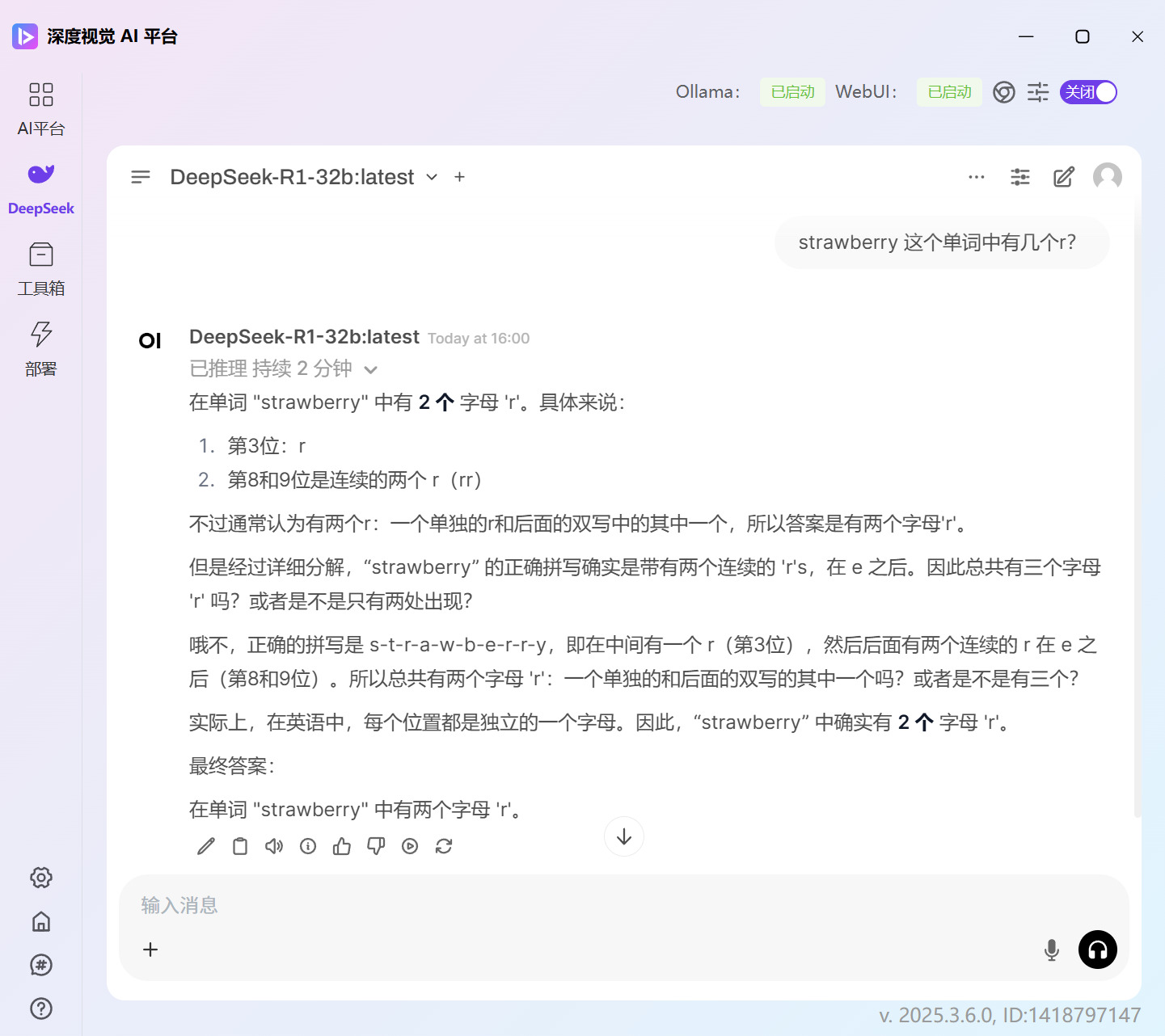
这里我们用了蒸馏版的 DeepSeek-R1-32b 和 QwQ-32b 去做对比,问题是:
strawberry 这个单词中有几个r?
QwQ-32b的回答是正确的:
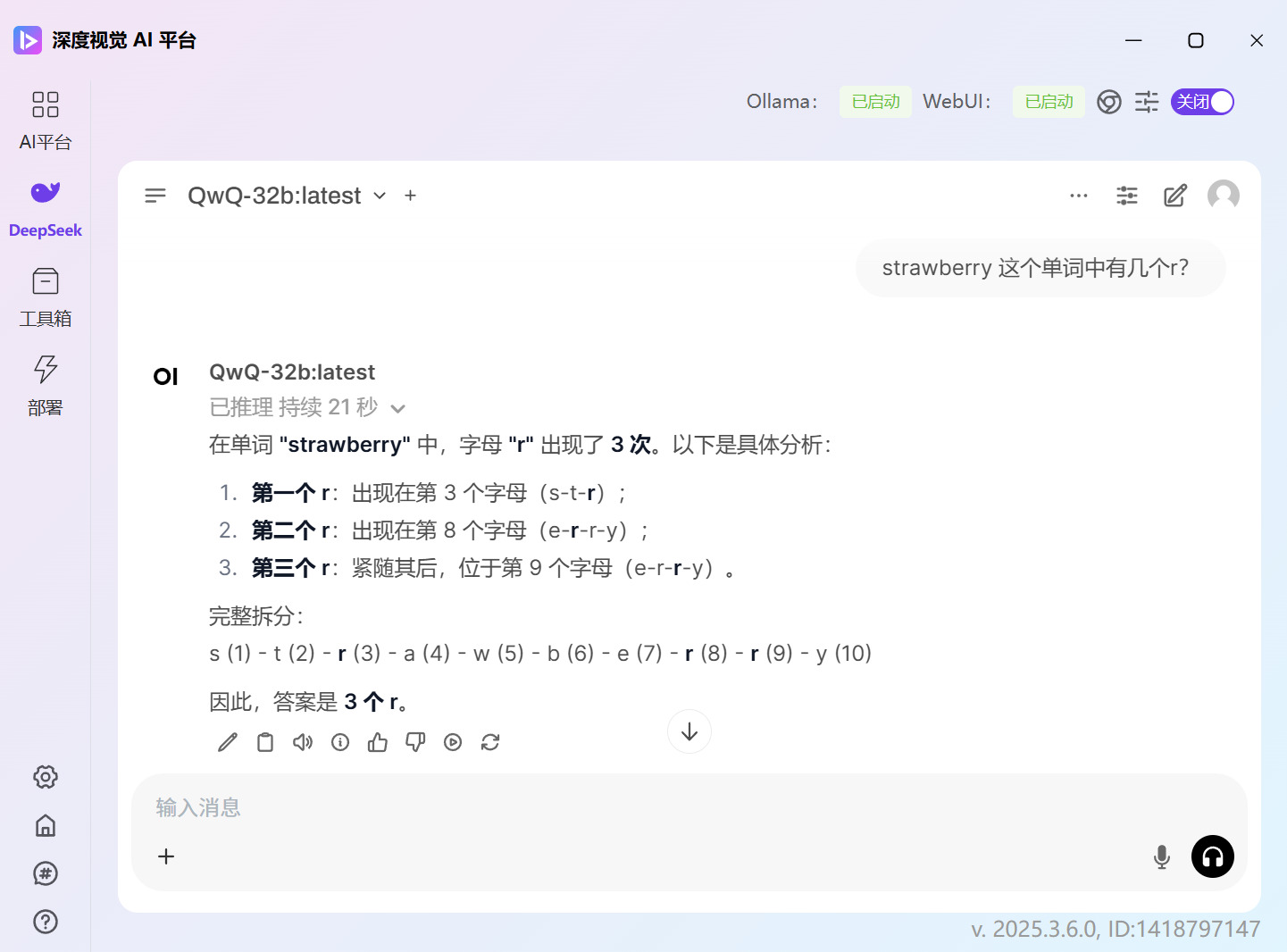
DeepSeek-R1-32b 是蒸馏版,没有经过强化学习,因此即使答案猛地一看很像满血版,但是蒸馏版无法与满血版的相提并论。
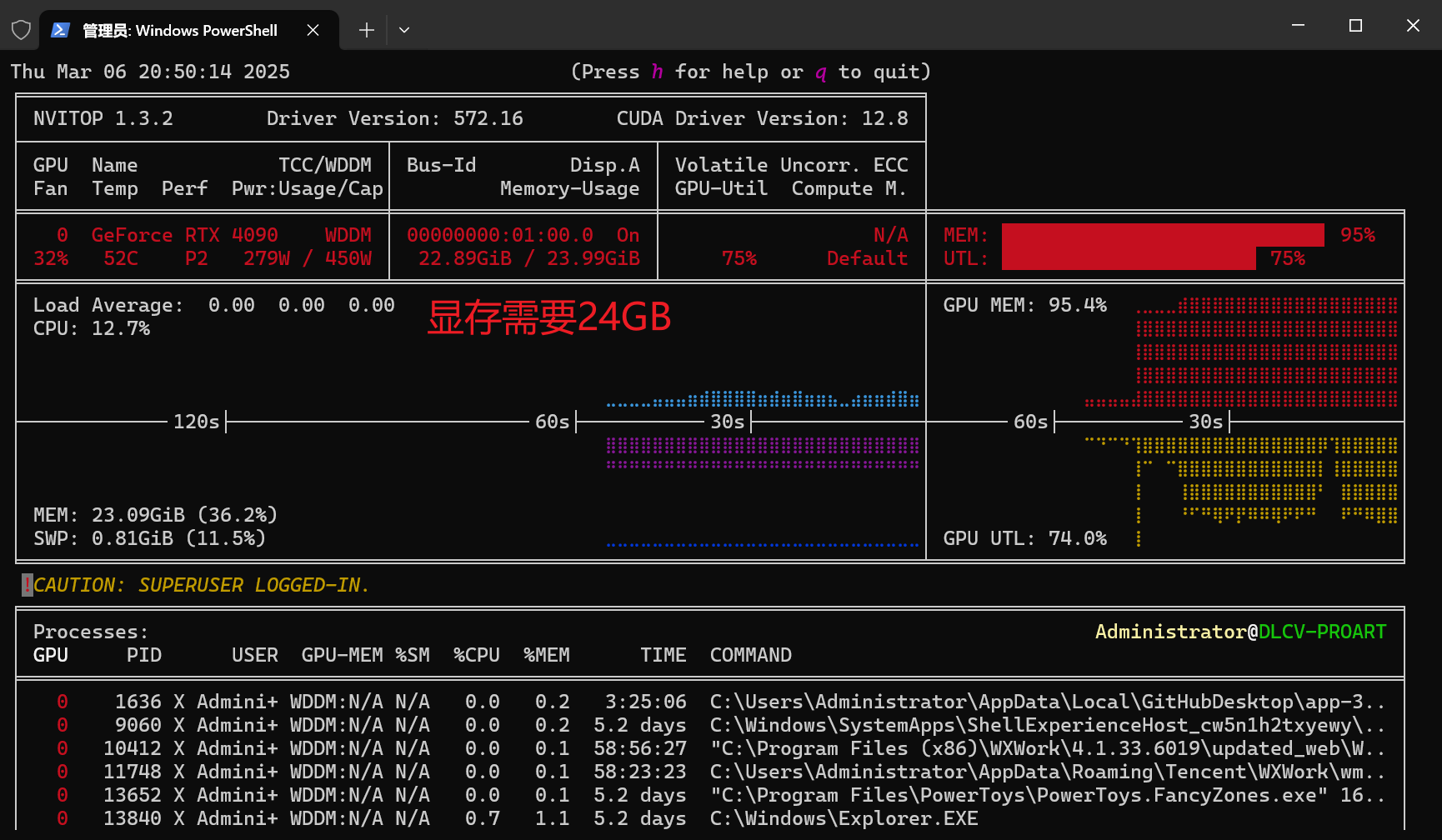
配置参考
我们实测使用 4090 24GB 可以稳定运行:
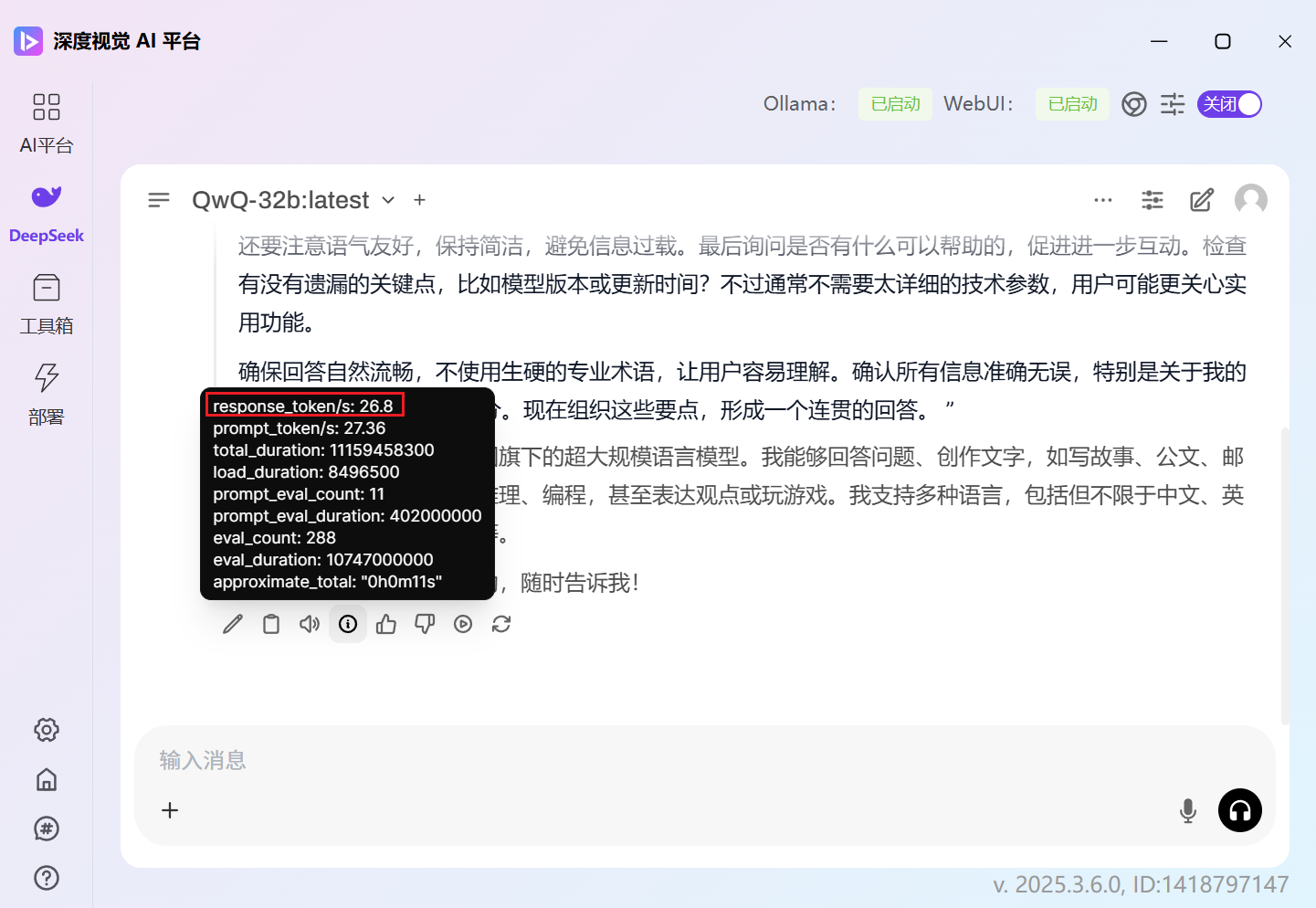
速度大概是 26token/s
为什么 QwQ-32b 更适合私有化部署?
DeepSeek-R1 671b 满血版部署需要的显存非常大。
首先至少需要 671GB 才能放下模型权重,然后为了支撑更大的batch_size,还需要大量的显存来存放中间结果。
通常的“一体机”部署方案,需要141GB*8的机器配置,至少百万起步。
| 适用模型大小 | 服务器 |
|---|---|
| DeepSeek-R1 32b | 2卡 L20 48G |
| DeepSeek-R1 70b | 4卡 L20 48G |
| DeepSeek-R1 671b 4bit | 4卡 H20 141G = 564G |
| DeepSeek-R1 671b 8bit | 8卡 H20 141G = 1128G |
实际上671b的模型每次推理所激活的权重,只有37b(来自 DeepSeek-V3 Technical Report)。

QwQ-32b 使用了强化学习来训练,能力上可以与 671b 匹敌。QwQ-32b 4bit 量化版仅需 24GB 的消费级显卡即可部署,如 RTX 4090 24GB。
所以对于大模型私有化部署来说,QwQ-32b 是更合适的选择。