文字识别
面向工业细分和复杂场景的OCR技术-支持中文

适用于工业细分和复杂场景的文字识别(OCR)任务是一个极具挑战性的领域,传统的OCR技术在此类场景下往往表现不佳。复杂场景通常包括:
- 背景复杂: 文字与背景颜色、纹理相似,或背景充满干扰信息。
- 版式不规则: 文字非水平排列,存在弯曲、扭曲、透视变形、任意形状文本(如印章、艺术字)。
- 字体多样: 非常规字体、手写体、艺术字或字体过小。
- 光照条件差: 曝光过度、光照不足、阴影覆盖、反光。
- 文字质量低: 低分辨率。
深度视觉的 OCR 技术融合前沿深度学习算法,它具备强大的抗干扰能力,在传统算法和预训练模型无法适配的工业细分场景及复杂场景下,经过一定数据的迁移学习,依然保持出色的稳定性和超高准确率。
- 支持训练:可以通过增加特定细分场景的数据来满足不同场景的应用需求。
- 支持文本种类多:能够精准识别包括中文、英文、数字及各类符号在内的多种文本内容。
- 高准确率:凭借先进的识别算法,我们在复杂场景下仍能保持极高的文字识别准确率。
- 高稳定性:系统经过长期优化与测试,在不同设备和环境中均表现出出色的稳定性和可靠性。
- 简单易用:用户界面简洁直观,标准化 SDK,无需复杂操作。
- 高效率:处理速度快,每秒可处理上千张图像,上万个字符。
应用案例
文字识别流程
1. 提取文本块
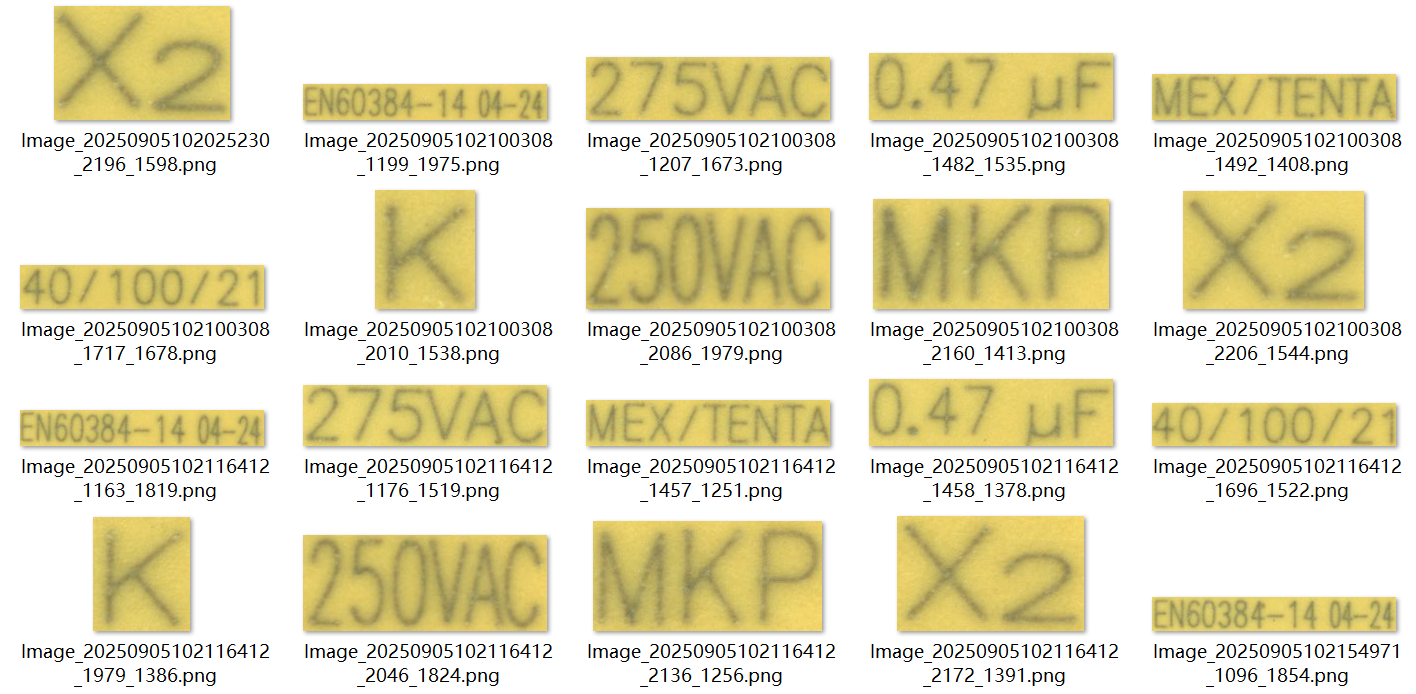
文字识别模型处理的是文本块,所以通常我们需要先在原图中定位到文本块,这一步可以使用目标检测模型、旋转框模型、传统算法等方式。文本块的划分按照断句习惯即可。
2. 对文本块进行标注(参考下面的标注说明)
3. 训练文字识别模型
文本块示例:
文件结构
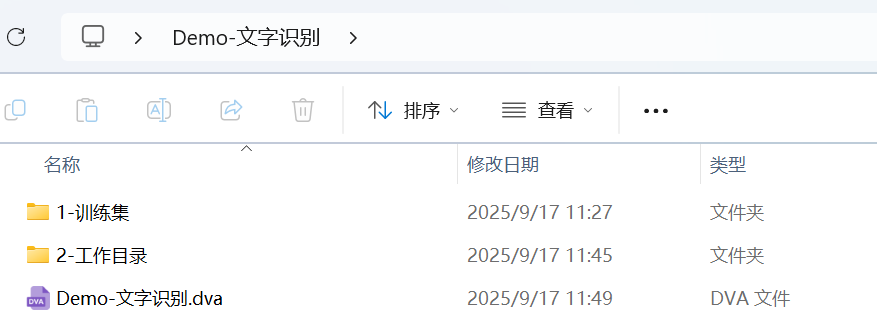
通常,我们将一个任务中的文件存放在一个文件夹下,包含:
- 1-训练集:存放训练数据,内部可以有多层文件夹,用户可根据使用习惯整理数据。
- 2-工作目录:存放训练完成的 AI 模型,日志,中间结果,过漏检数据等。
- AI 项目文件:后缀名为.dva,创建项目后自动生成在训练集同目录下,记录项目信息和训练参数等。
任务文件夹
工作目录
文字标注
- 文本块的标注需要使用 LabelmeAI。
- 在标注软件中打开需要标注的图像文件夹。
- 使用快捷键 T,弹出文本标注框,输入正确的文本即可。
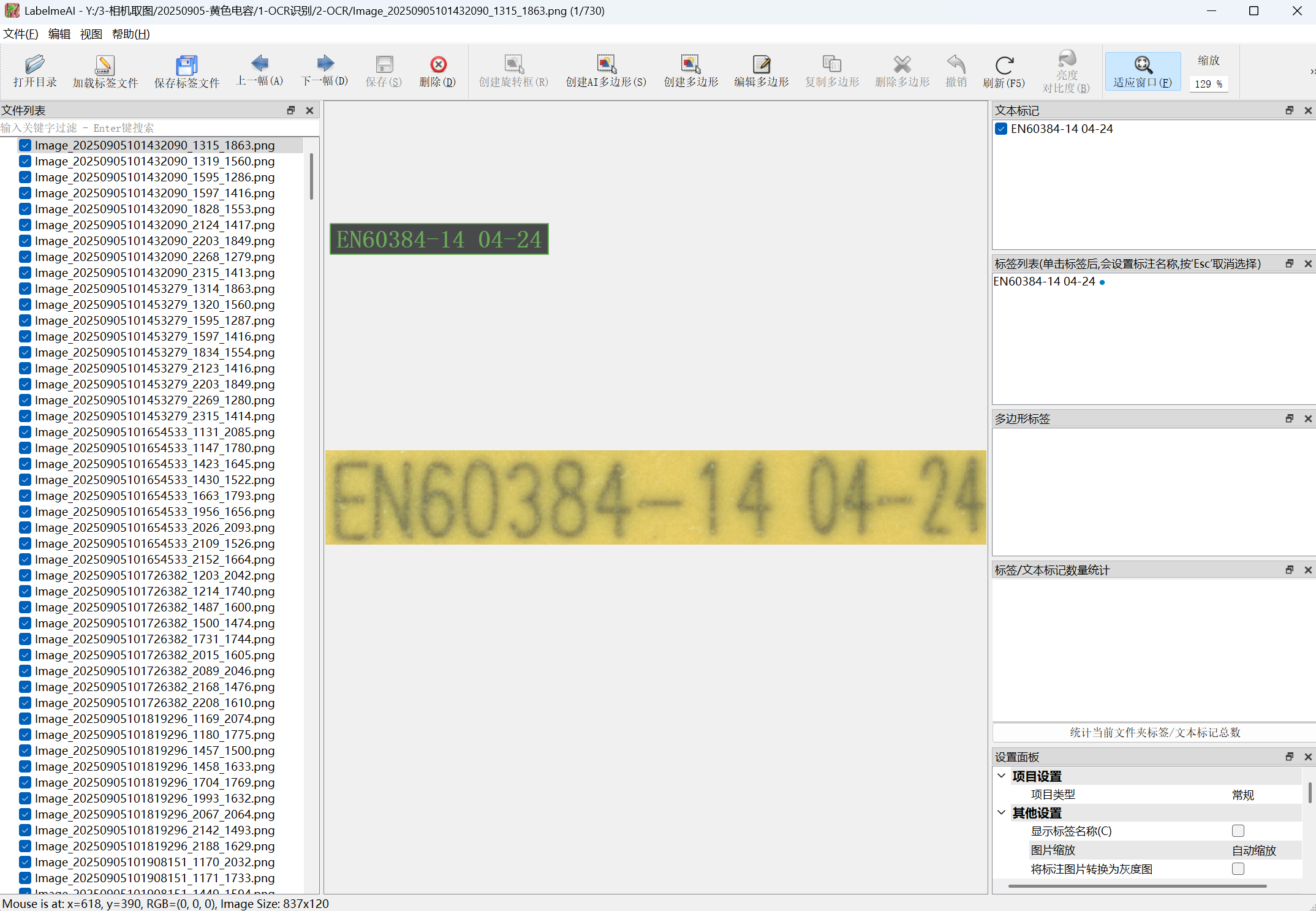
- 经过硬件锁授权后,文本支持使用预训练模型或私有模型进行自动标注。
标注文件
标注完成的图像会在同目录下生成 json 文件,文件名与图像名称相同,后缀为 json。
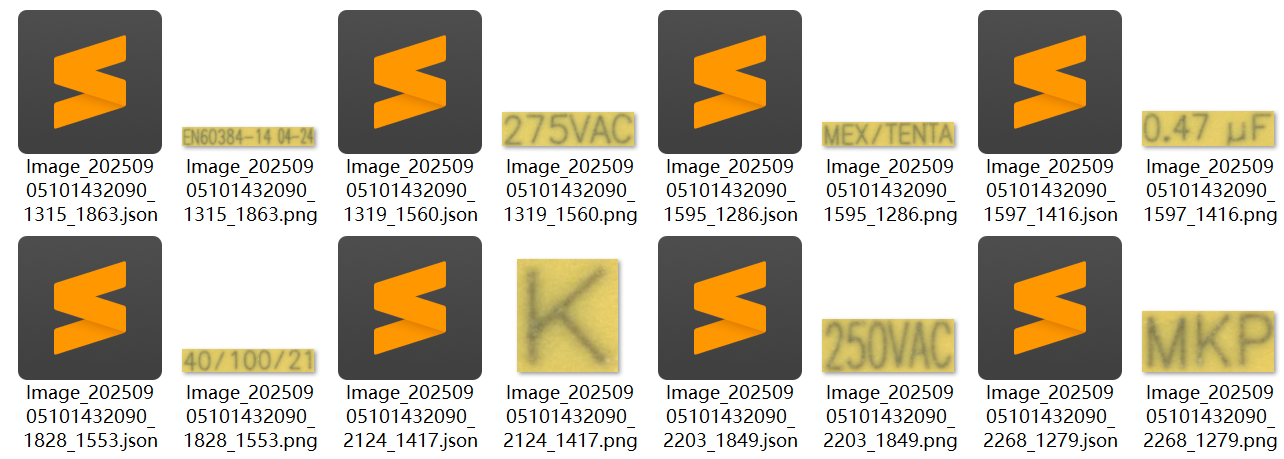
文本标记示例:
{
"version": "2025.9.11.0",
"flags": {
"275VAC": true
},
"shapes": [],
"imagePath": "Image_20250905101654533_1147_1780.png",
"imageData": null,
"imageHeight": 114,
"imageWidth": 443
}
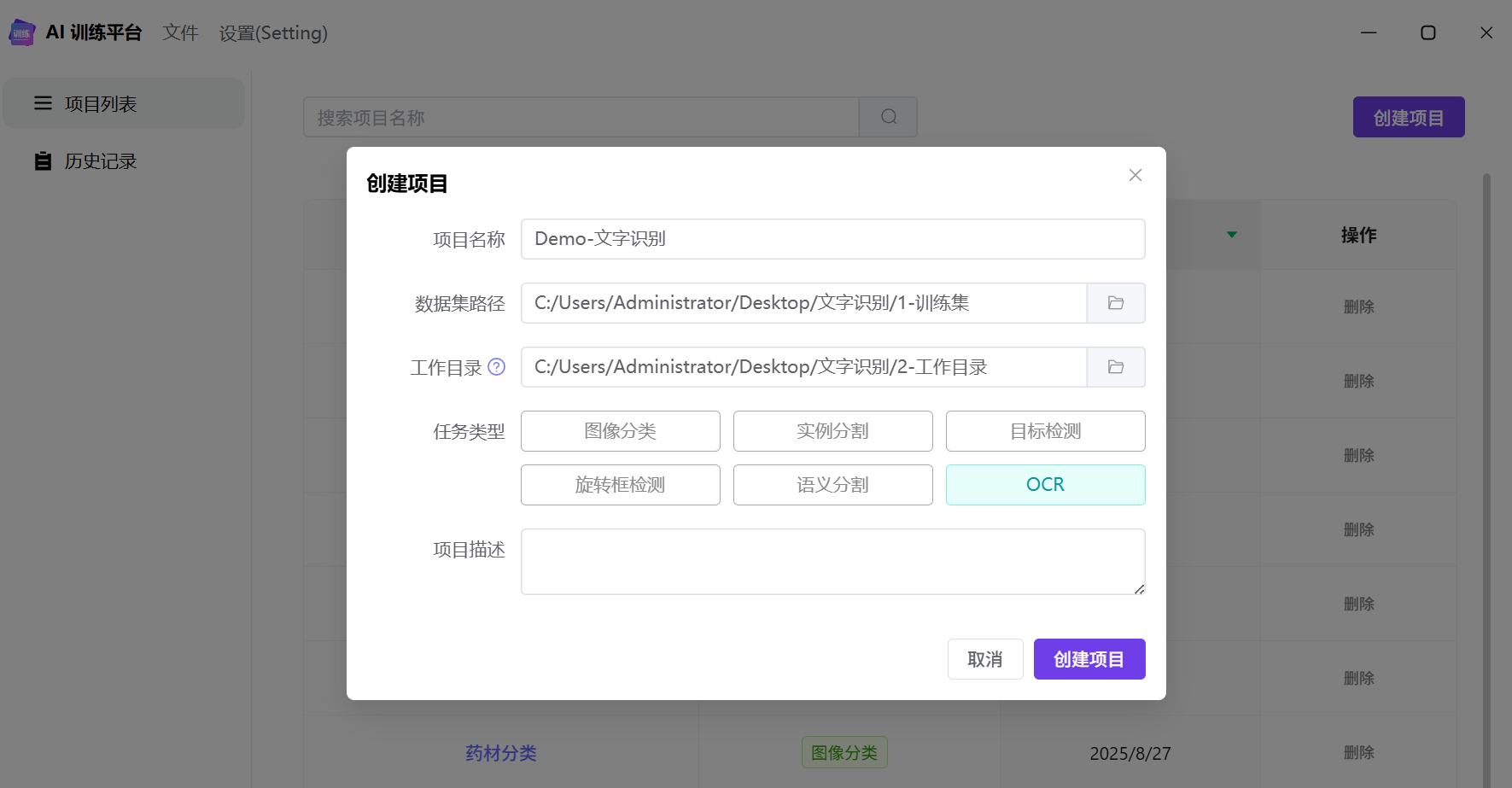
创建项目
任务类型选择【OCR】
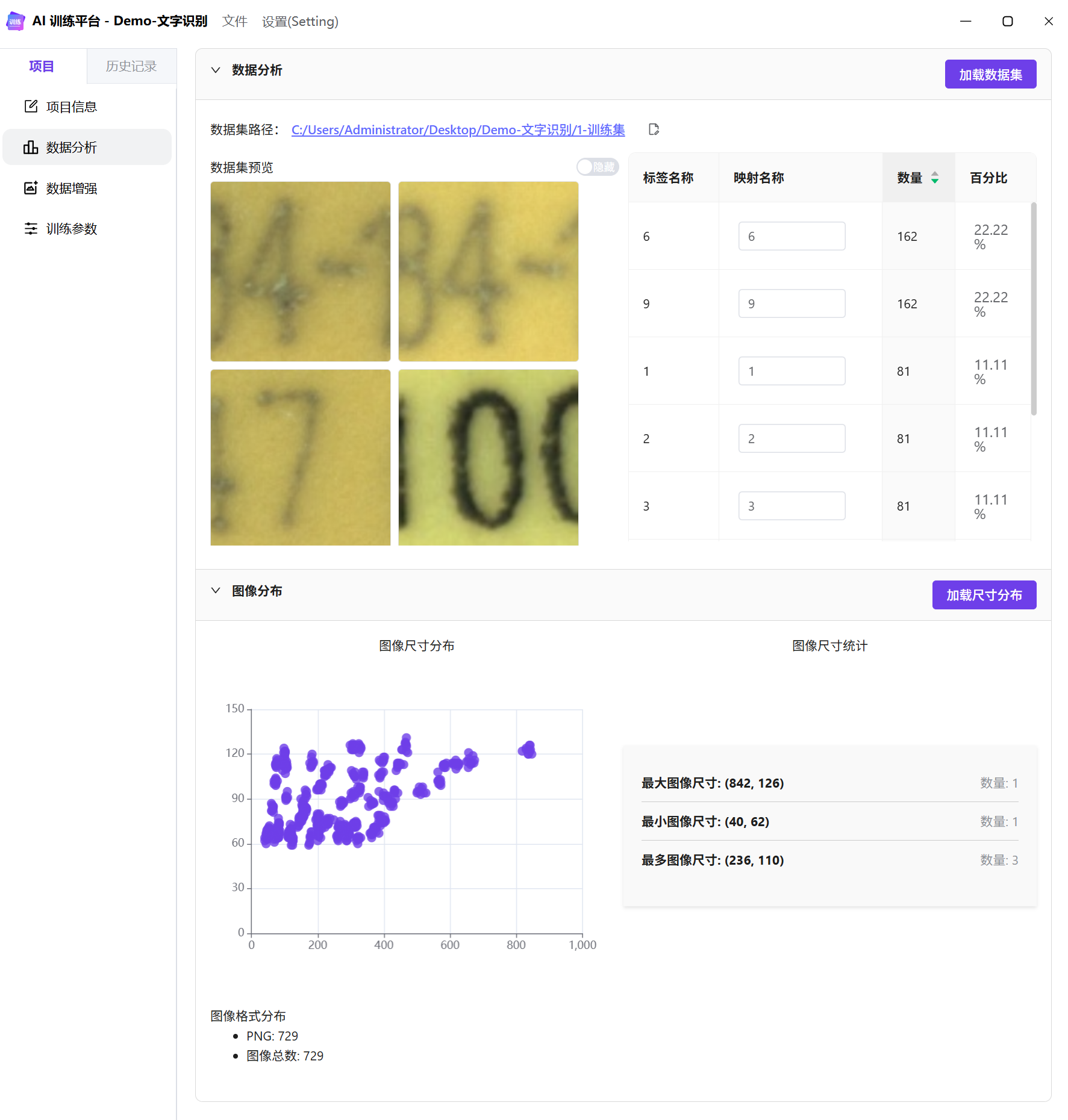
数据分析
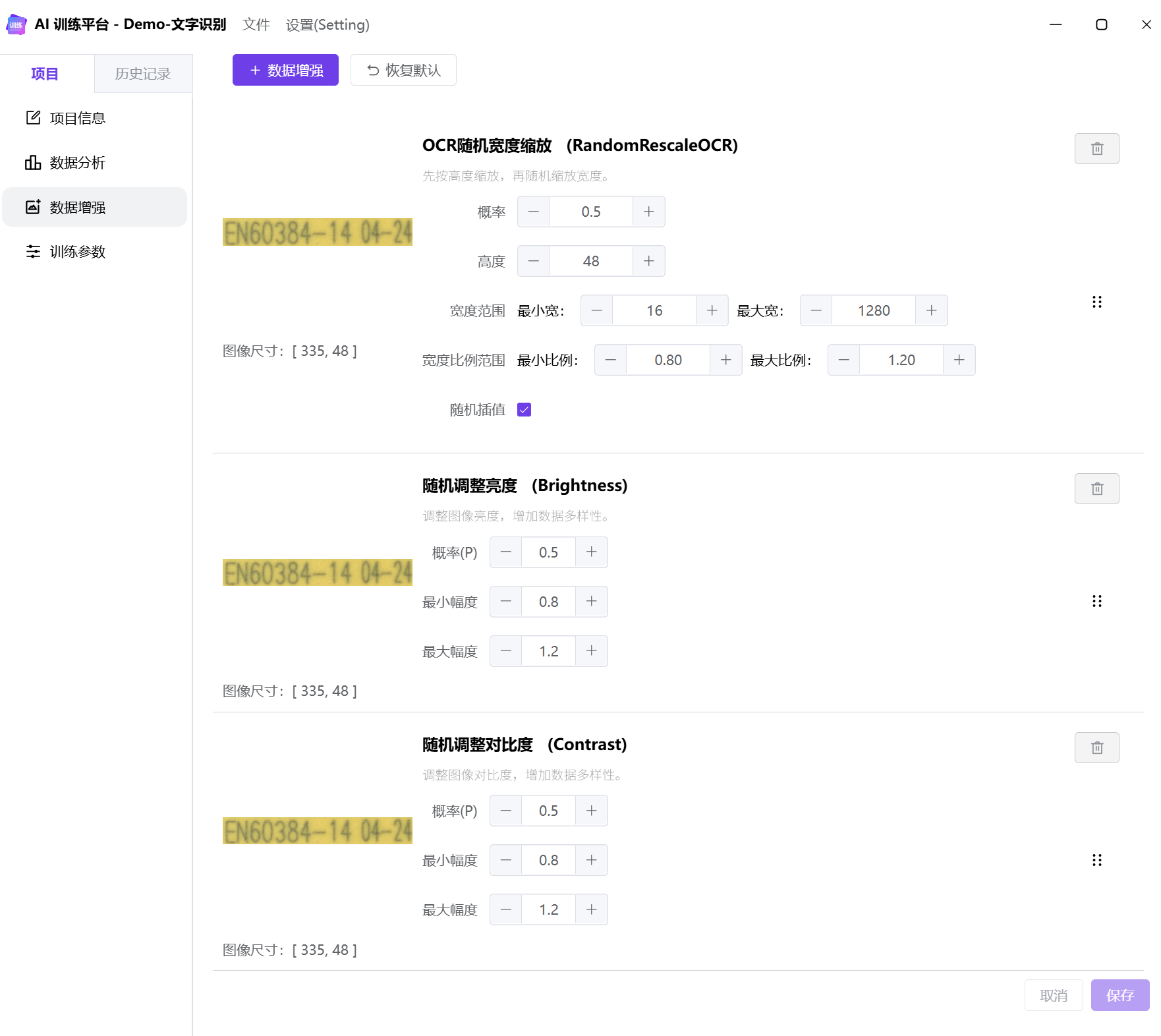
数据增强
训练参数
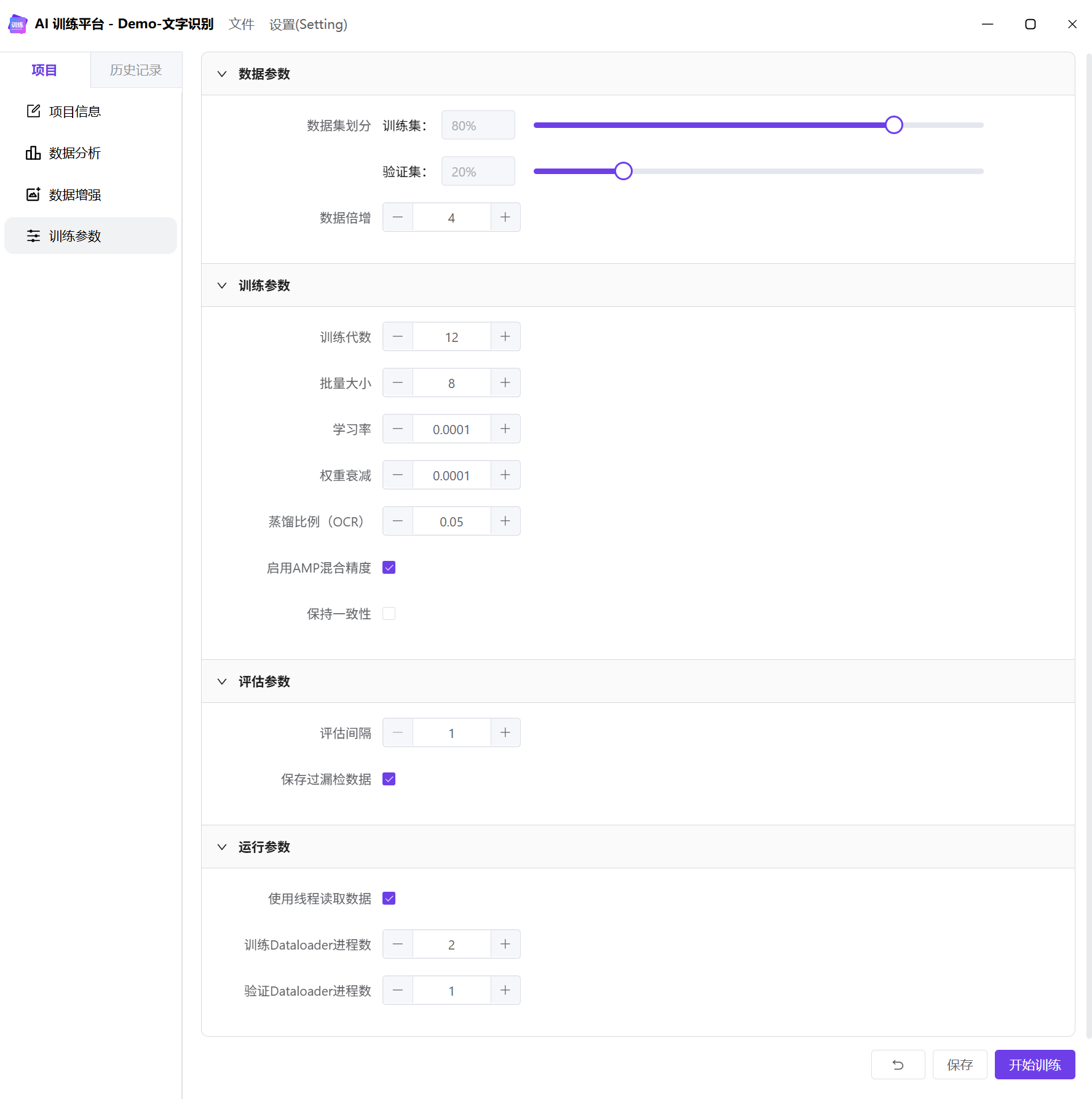
- 训练集和验证集的比例通常为 8:2;如果希望看到所有数据的评估结果,可以将验证集比例设置为 100%。
- 蒸馏数据集占比,默认0.05,蒸馏比例越大,用户数据集比例越小,模型原有能力越强,泛化性能越好,但是用户数据识别能力越弱。
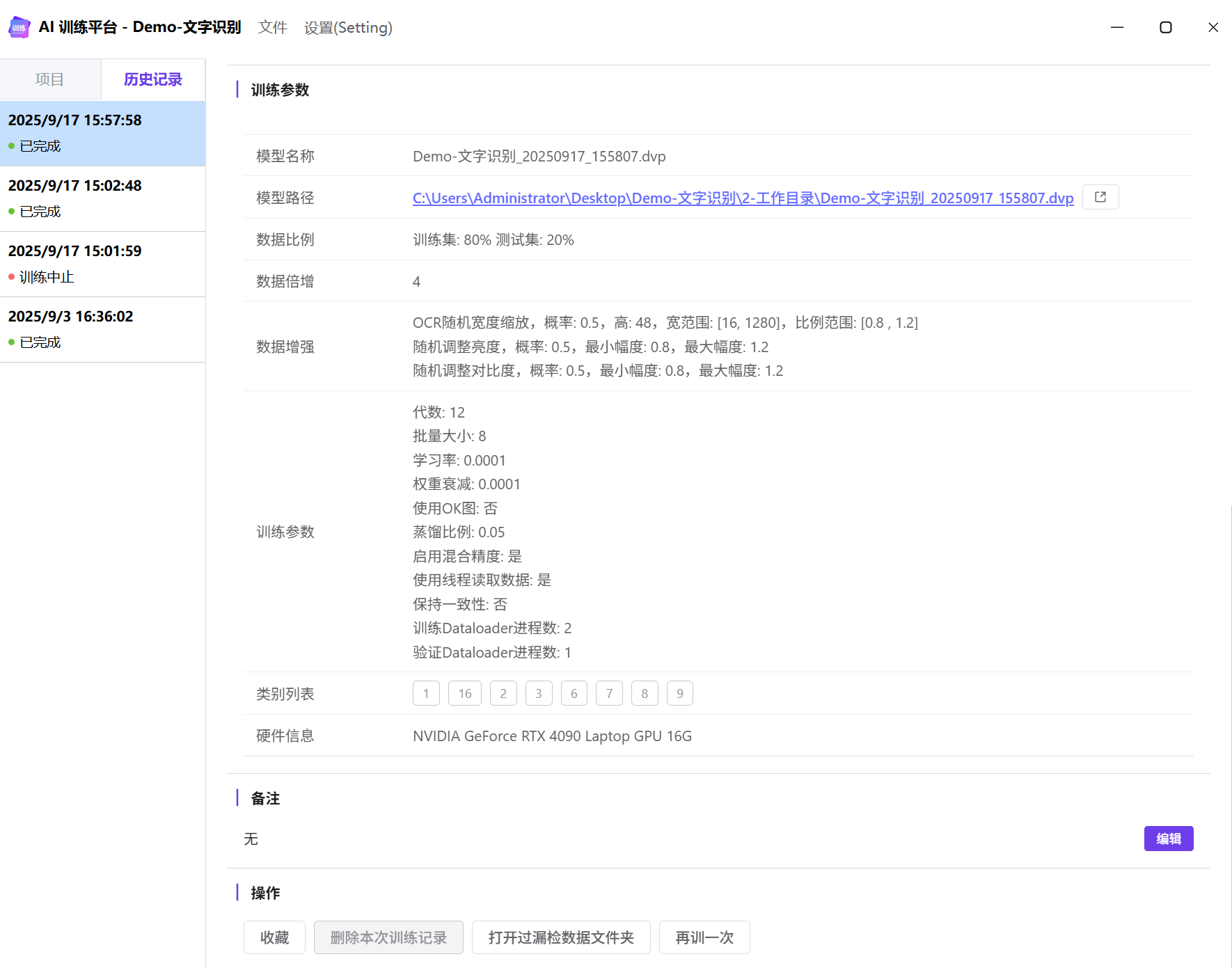
训练记录
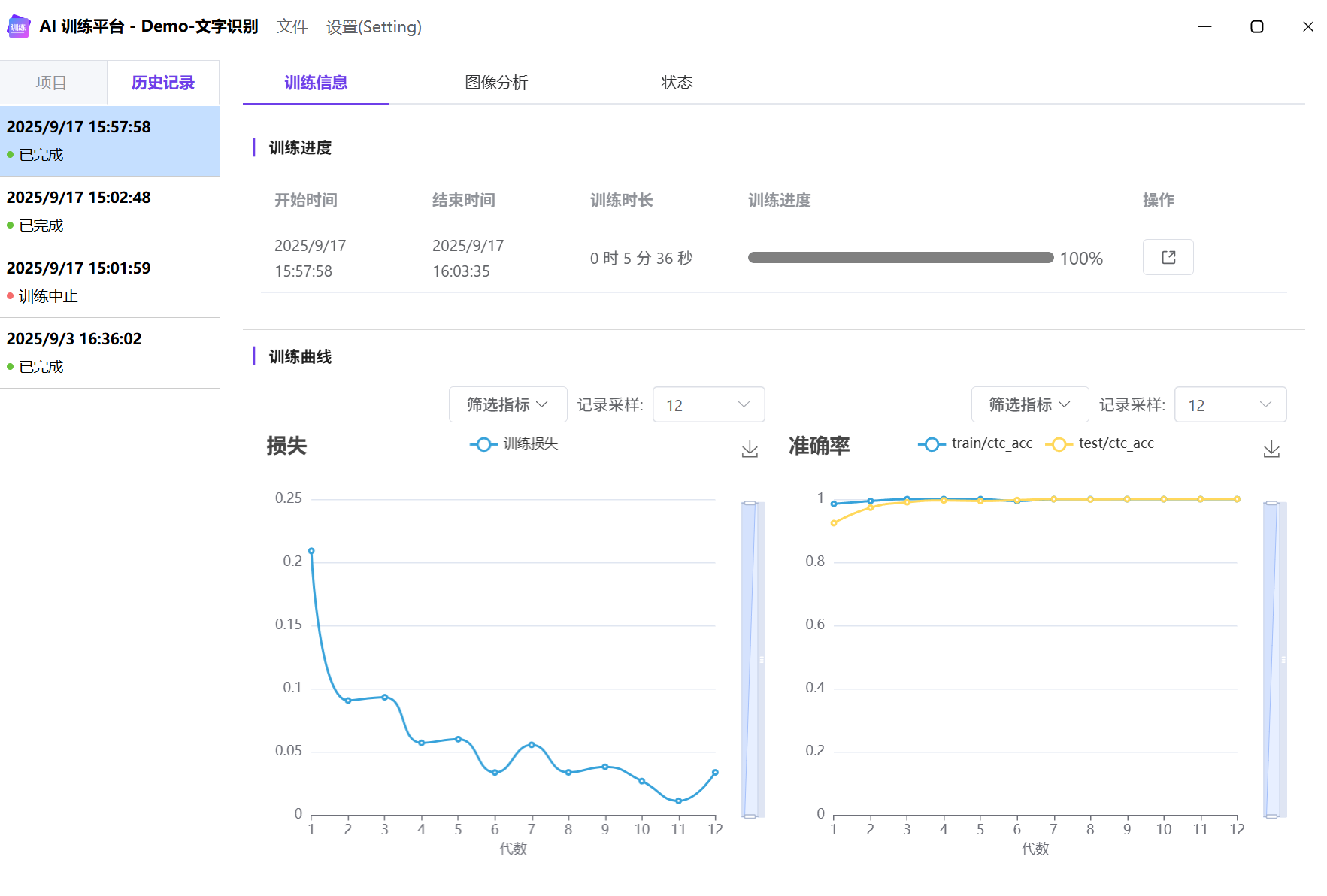
准确率和推理速度
经过数据训练的文字识别模型的准确率通常在 99% 以上,单文本块推理速度 2-10ms,根据显卡配置或文本长度不同有波动。
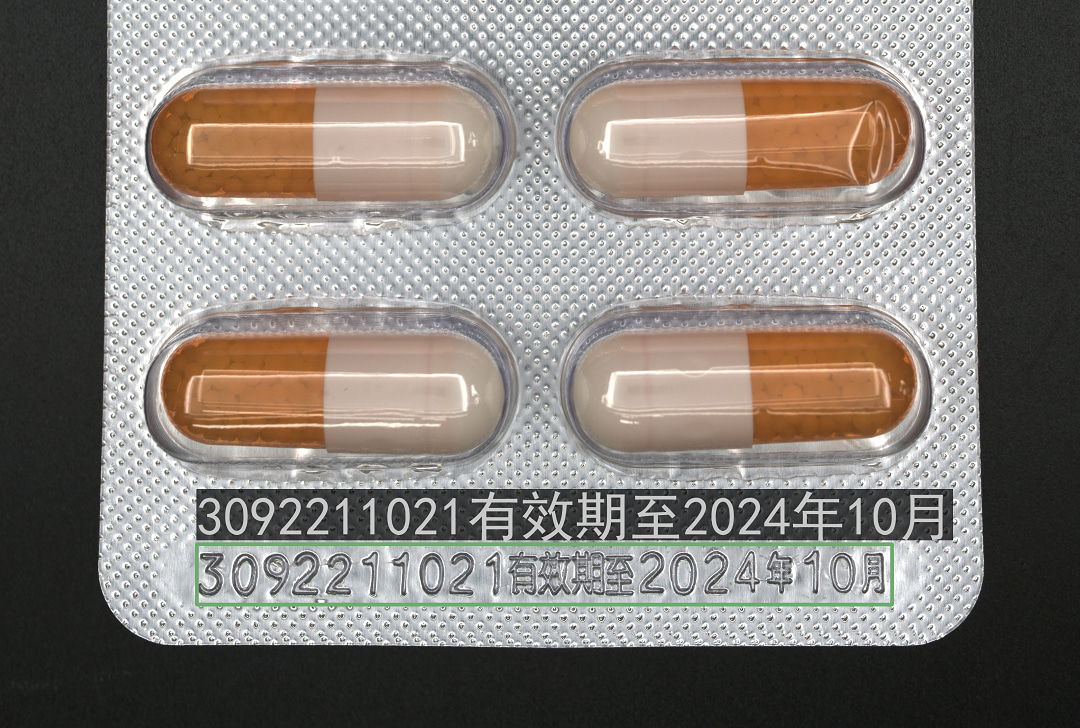
应用案例
效期识别
激光打标

PCB

元器件
