语义分割
语义分割模型为图像中的每个像素分配一个语义类别标签。与实例分割(区分同类物体的不同个体)不同,语义分割仅关注类别级别的区分。我们使用了一种创新的语义分割模型,通过并行多分辨率分支始终保持高分辨率特征,避免传统编码器-解码器结构中的信息丢失。
应用场景
- 裂纹检测
- 提取图像中的主体轮廓
- 精细的边缘查找
应用案例
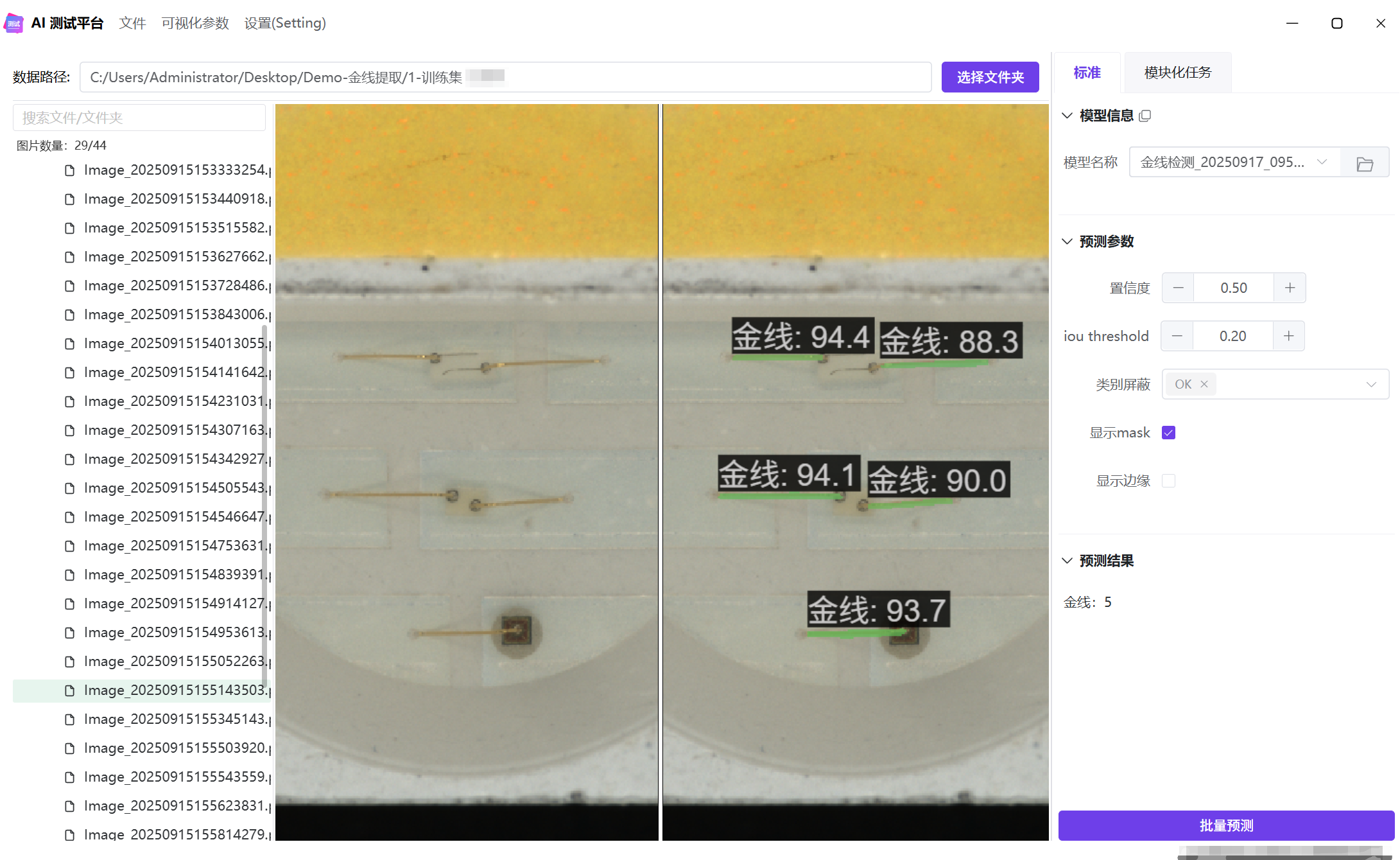
这是一个使用语义分割进行金线提取的案例,在这个任务中,不必须要 NG 图像。仅使用良品也能准确提取金线。 在准确提取金线后,通过对金线长度 ,位置,数量等判断是否存在异常。

文件结构
通常,我们将一个任务中的文件存放在一个文件夹下,包含:
- 1-训练集:存放训练数据,内部可以有多层文件夹,用户可根据使用习惯整理数据。
- 2-工作目录:存放训练完成的 AI 模型,日志,中间结果,过漏检数据等。
- AI 项目文件:后缀名为.dva,创建项目后自动生成在训练集同目录下,记录了项目信息和训练参数等。
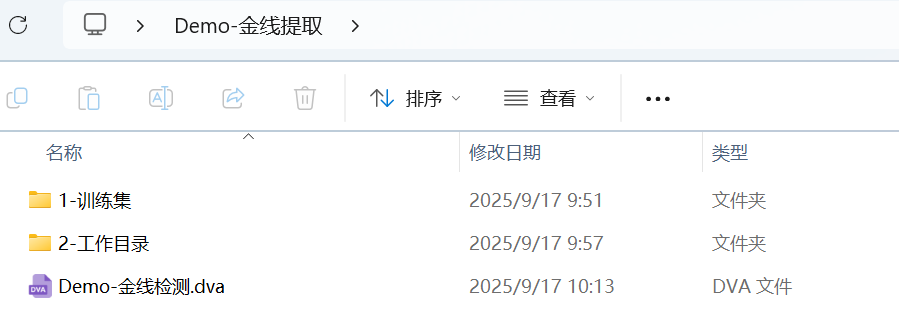
在训练集中,支持相似的产品混合训练。可以按照产品型号,特点等对训练集数据进行整理:
数据集准备
使用 Labelme 标注数据
- 手动标注
- AI 辅助标注:基于大模型的轮廓自动提取,仅需手动选择标签。
- AI 自动标注:支持使用预训练模型或定制化模型批量标注,仅需人工核查。(此功能需要硬件加密锁授权。)
参考:Labelme基本功能
精细的轮廓提取可以在使用 AI 辅助标注后人工进行边缘的修正。使用数十张图像训练的 AI 模型进行自动标注也能瞬间提升效率。
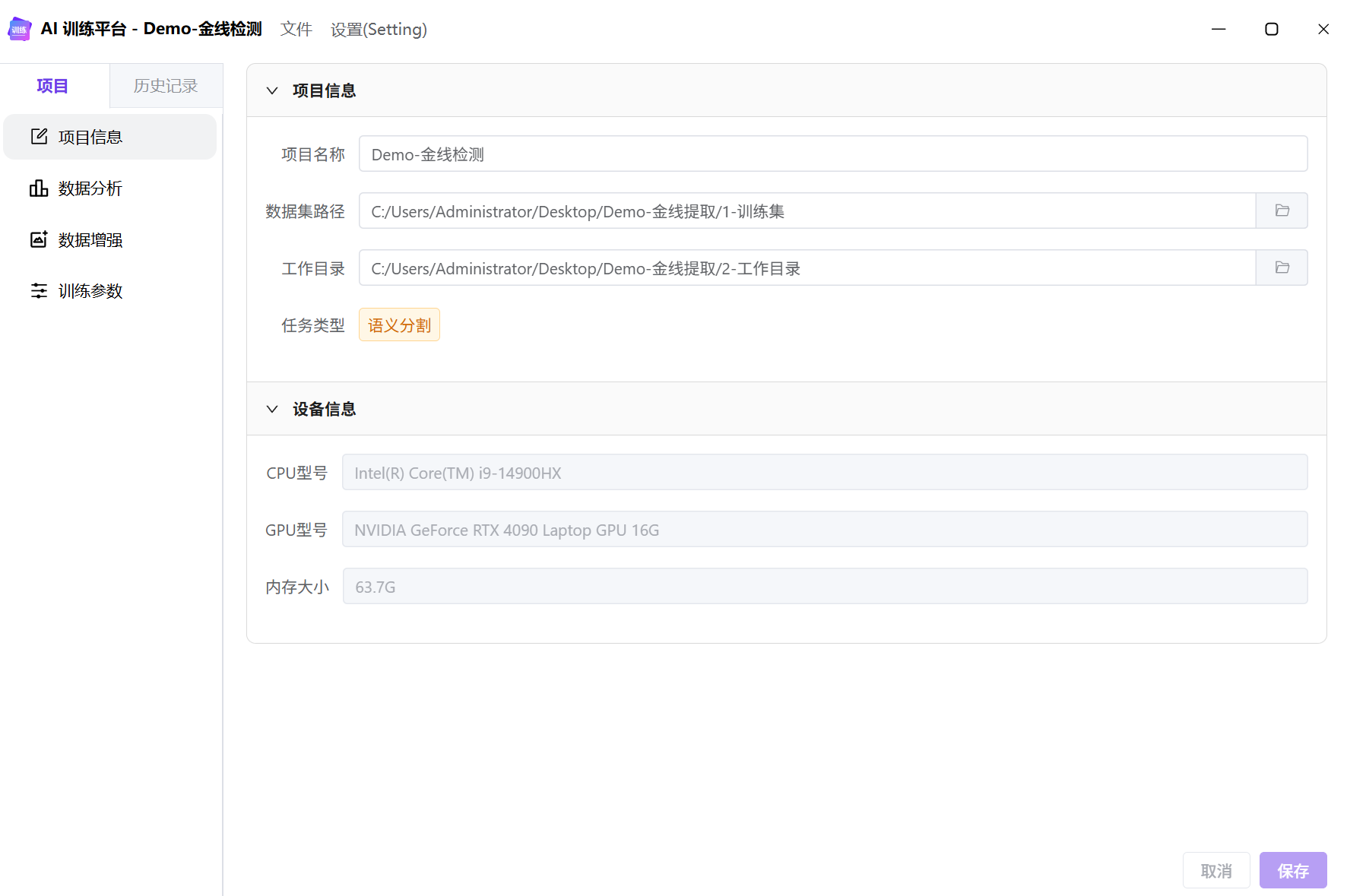
项目信息
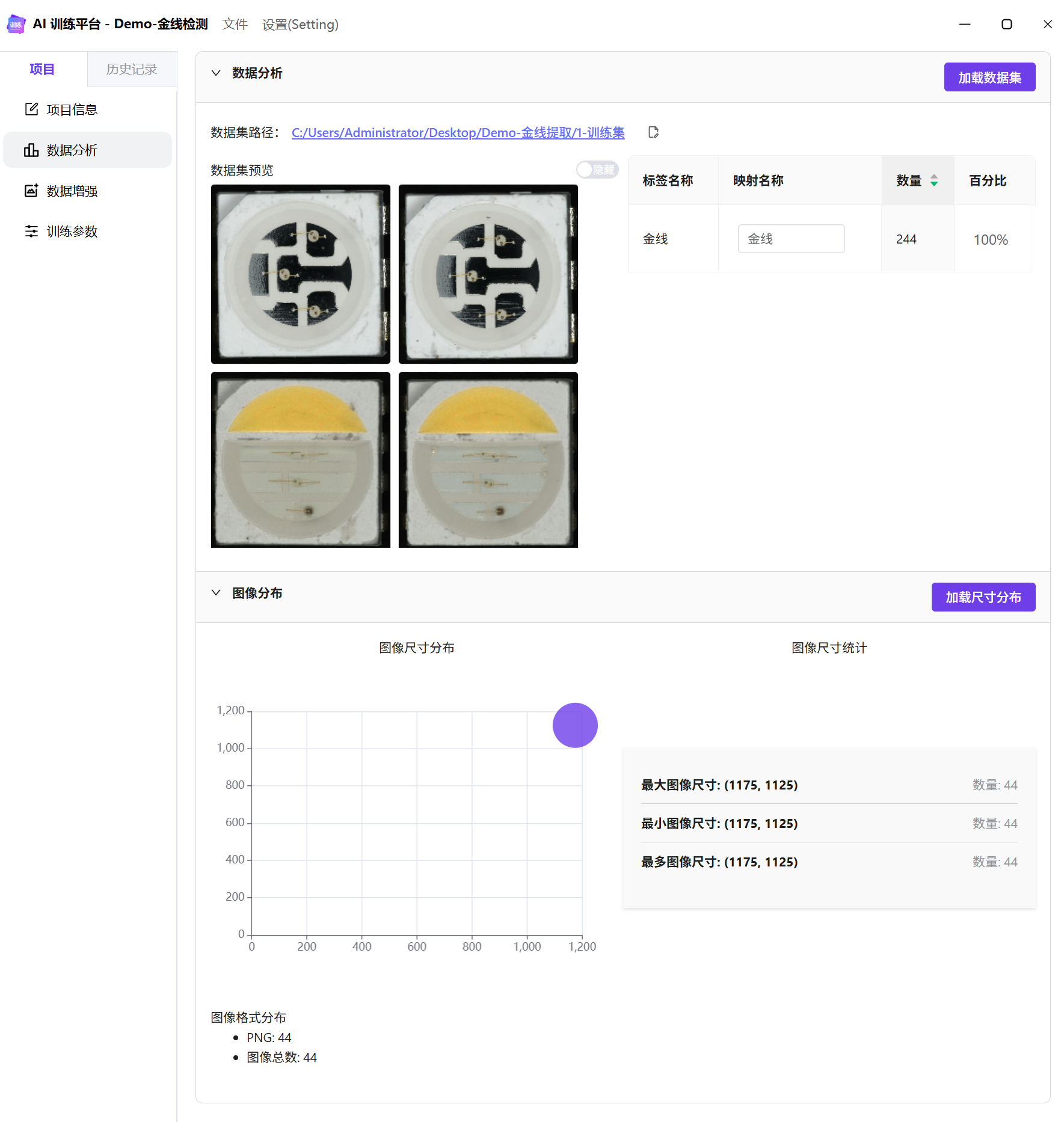
数据分析
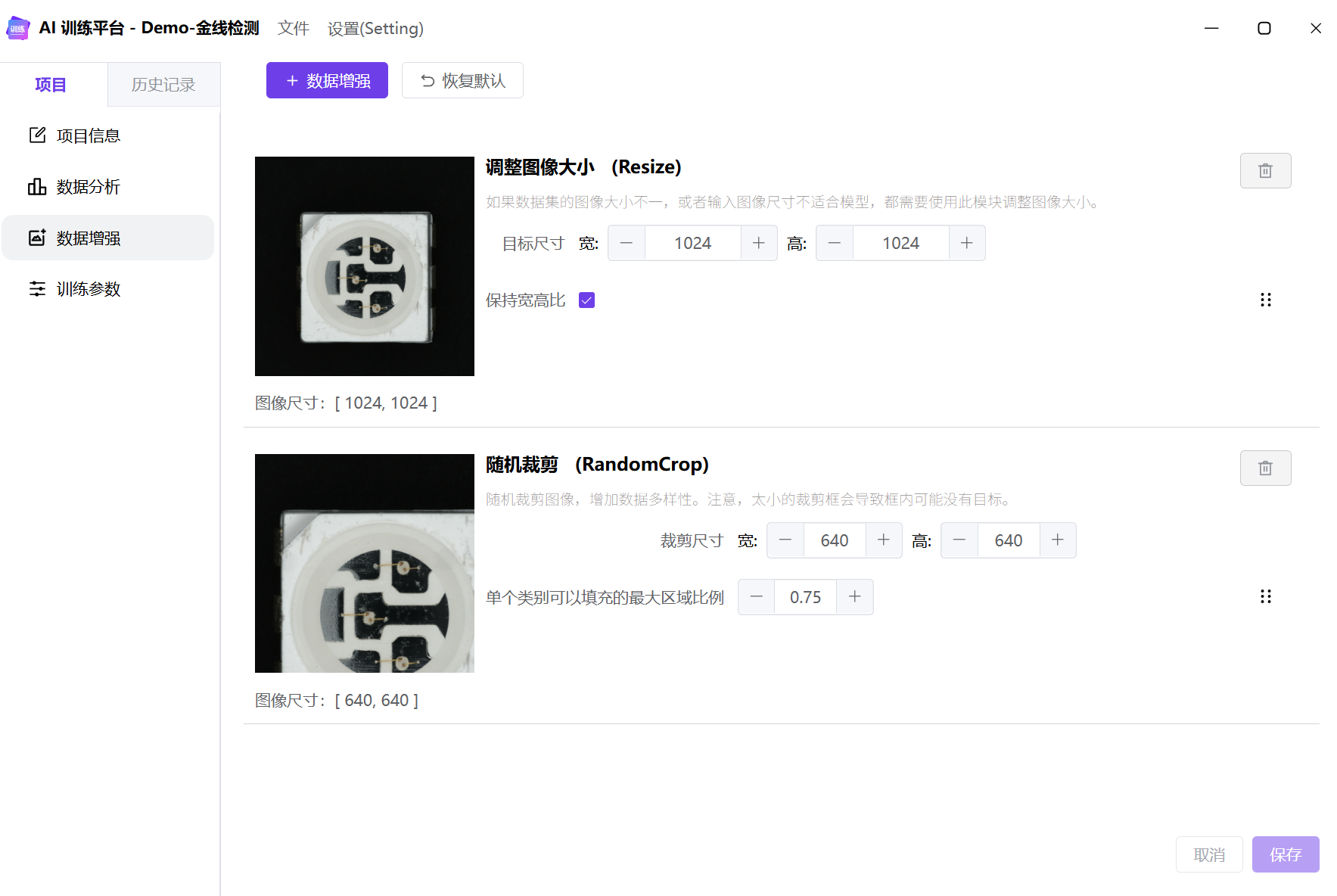
数据增强
调整图像大小
原图尺寸是 1175×1125,在训练过程中,我们优先选择 32 的倍数作为训练尺寸。在这个任务中,需要检测的金线较细,所以选择与原图尺寸接近的尺寸,为 1024× 1024。
Tips:训练尺寸越大,能够检测的越精细,同时训练时间和推理时间也会增加。需要根据图像尺寸,检测目标尺寸范围综合评估一个合适的参数。
注意:语义分割模型使用 dvt 部署时要选择 32 的倍数。不考虑部署或使用 dvp、dvo 部署时不强制使用 32 的倍数,但是使用 32 的倍数仍然是更好的选择。
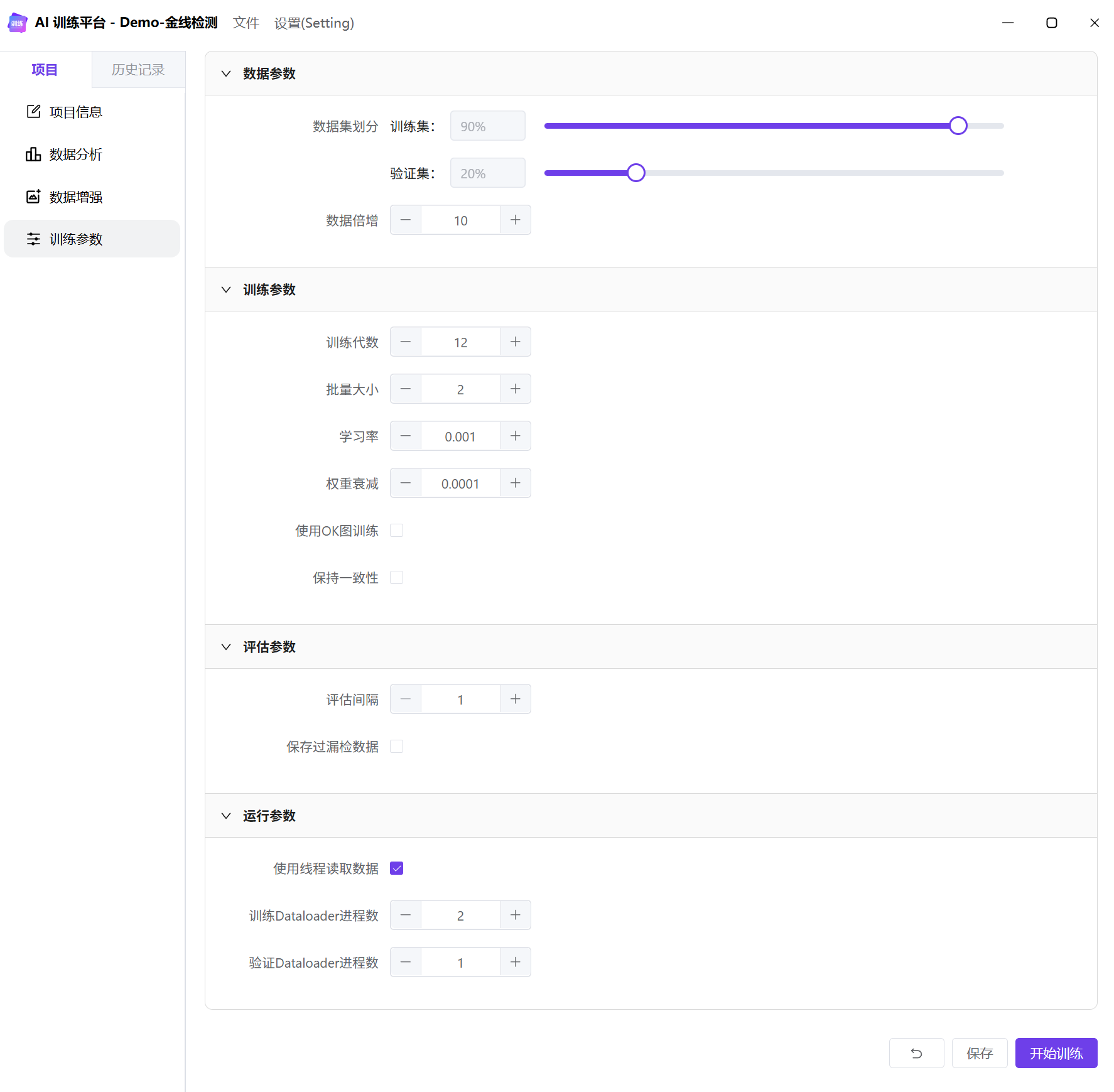
训练参数
训练集与验证集
通常训练集与验证集的比例为 8:2,数据量较小时,建议增加训练集比例,最多可增加至 100%。数据量很少时,会将训练集和验证集都设置为 100%。此时,模型在训练集上效果通常不错,但是在新数据上的结果可能不稳定。
- 训练集比例+验证集比例小于或等于 100% 时,训练数据不会参与验证
- 训练集比例+验证集比例大于 100% 时,部分训练集参与验证
数据倍增
在初期数据量较少,数据倍增参数设置为 10-20;随着数据增加,数据倍增参数相应减少,通常为 5、4、2,数据量极大时(>2000),设置为 1。
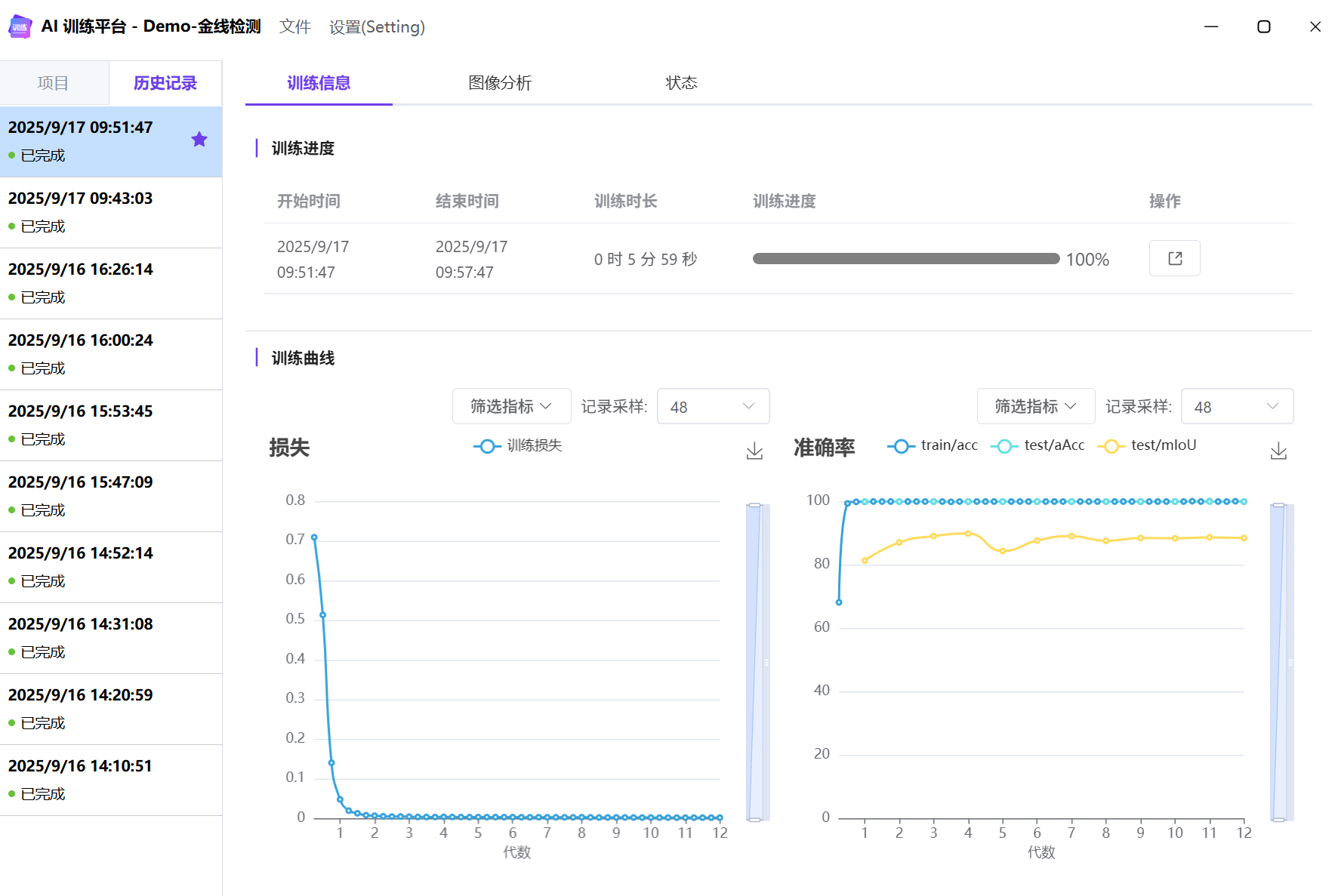
训练记录
AI 模型测试

AI 平台下载