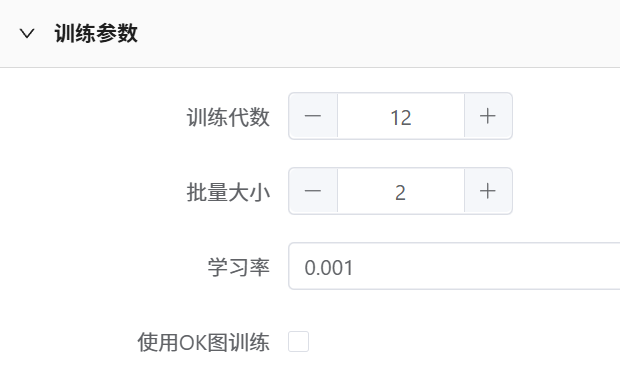
训练参数
训练代数
训练代数默认12,无需修改。202605之后的版本关闭了修改接口。
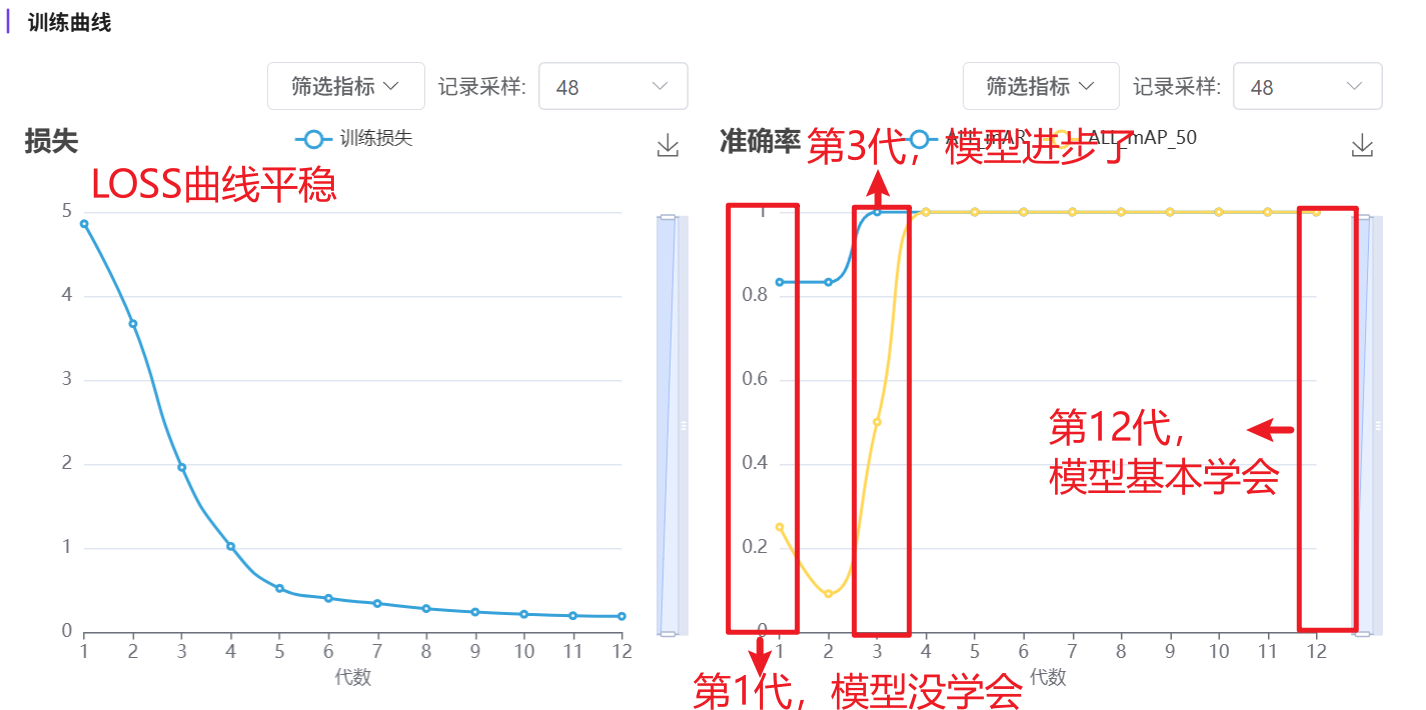
1 个 Epoch = 模型把全部样本从头到尾学习了 1 遍。
12 个 Epoch = 模型把全部样本反复学习了 12 遍。
通常模型在学习第1遍时可能没掌握,在学习第3遍明显进步,在学习第12遍基本掌握。
批量大小
分类默认批量大小32,检测类模型批量大小默认2。
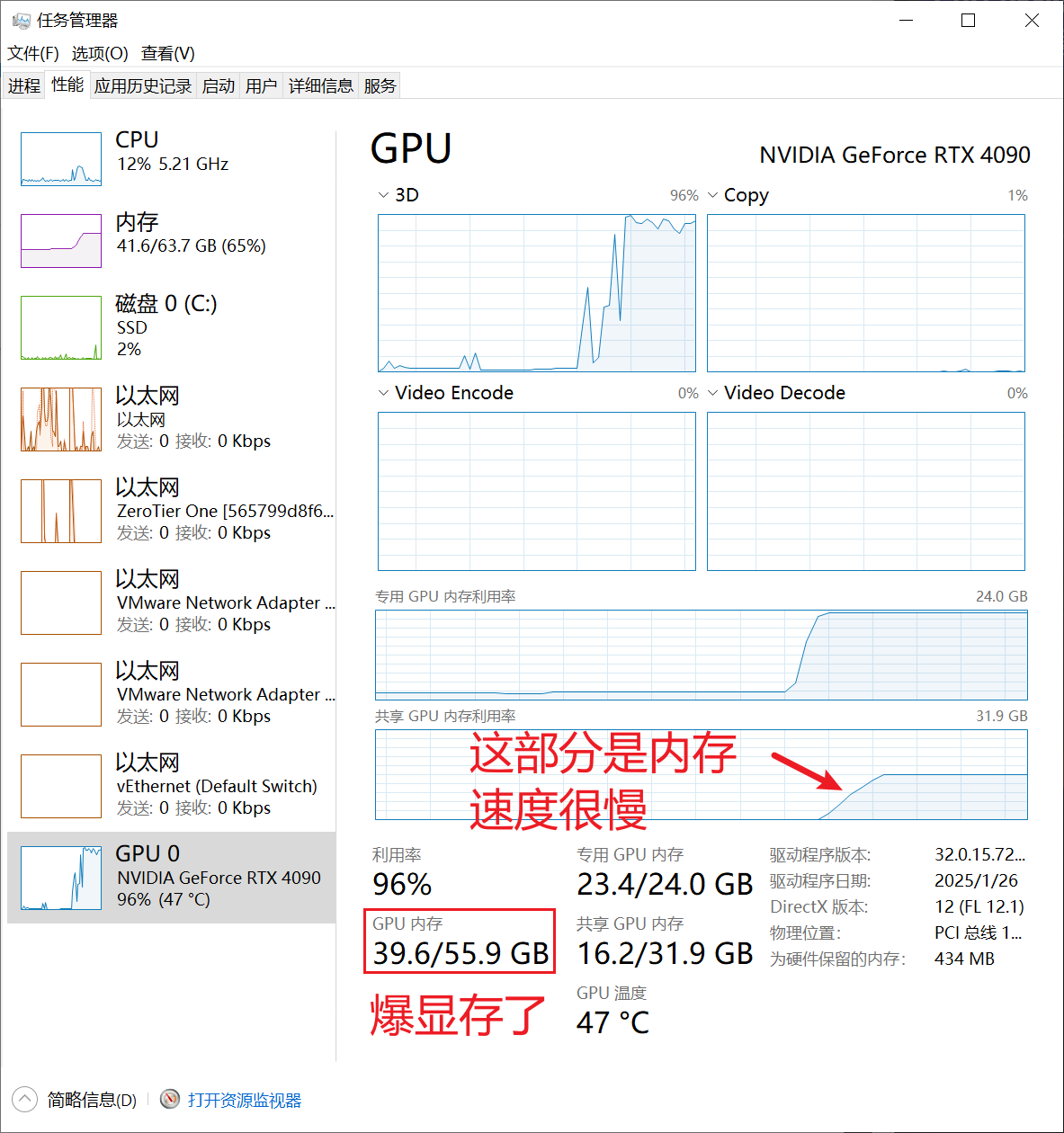
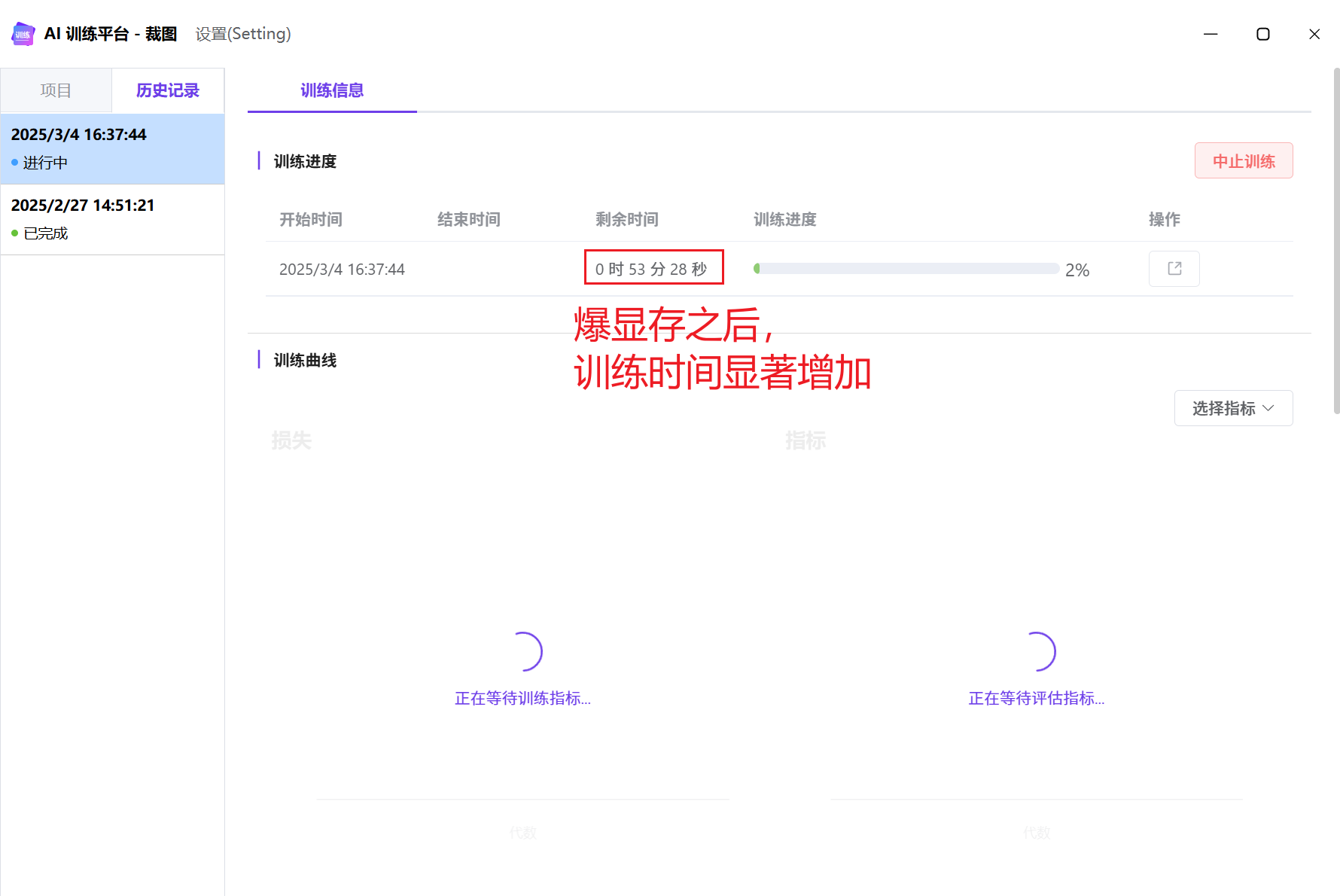
当图像尺寸比较大时(比如2048),可以适当降低批量大小,避免爆显存导致训练时间过长。
爆显存示意图:
Mask放大系数(仅实例分割,加密狗功能)
仅用于实例分割模型的一种数据增强,默认值为1。

当遇到 物体边缘\轮廓需精细检测 场景时,可以将值调整为 2,需要注意的是,值越大时,训练及推理时间会越长。
学习率
实例分割模型默认学习率为 0.001;通常不需要调整,但是当 loss 曲线比较震荡时,可以考虑降低学习率,通常减低为 0.0005 或 0.0001。
训练 loss 不稳定
下图可以看到 loss 出现了“插针”的现象,突然变很高,又回归正常。
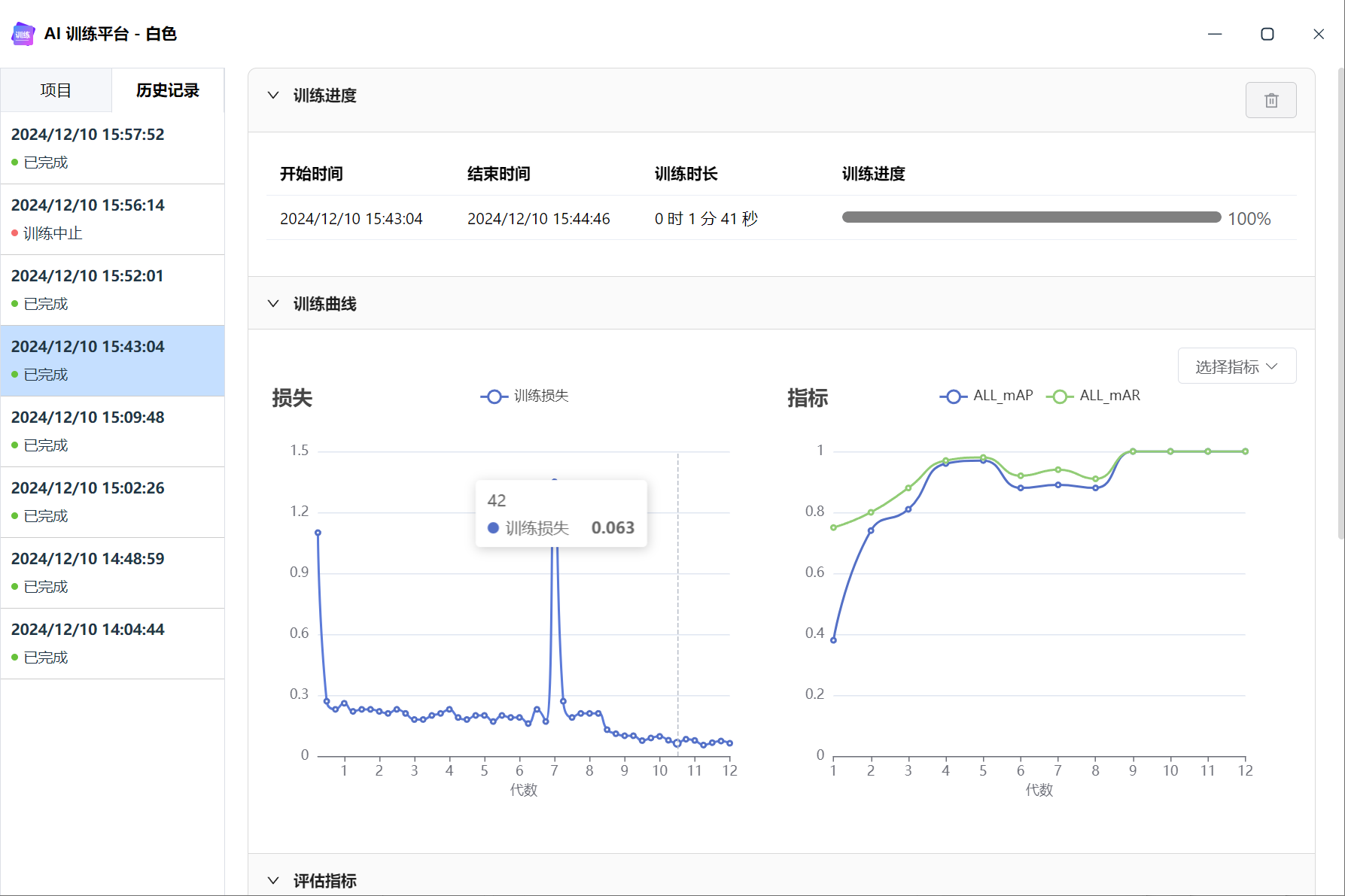
震荡的 Loss 曲线⤵️:

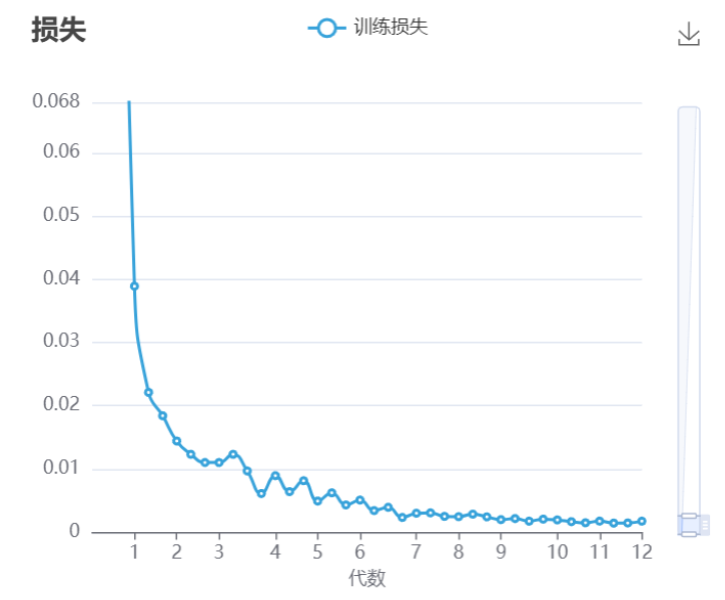
平稳的 Loss 曲线:
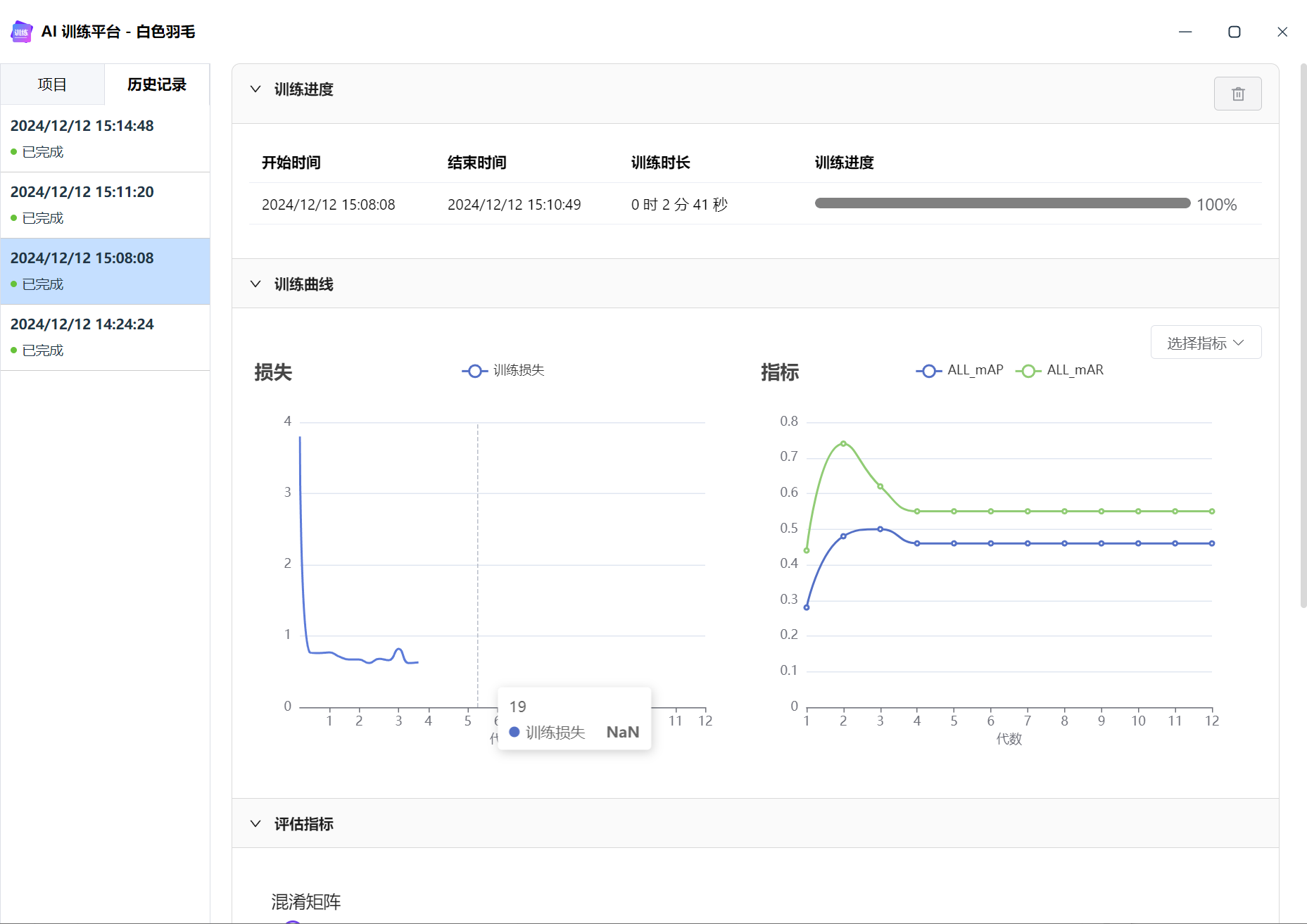
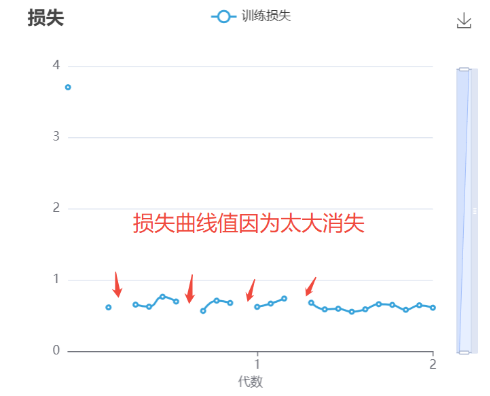
训练 Loss NaN
AI 模型在训练过程中,可能存在损失函数(Loss)的计算结果变成非法数值(如NaN、inf等),导致训练崩溃的现象。
造成 Loss NaN 可能的原因:
- ○训练数据中存在过多重复数据,重复数据可能导致模型在训练过程中对某些特征过度敏感,梯度在反向传播时不断累积,最终数值溢出。
- 标注中存在异常,如多边形越界,多边形交叉等。
✔️ 解决方法:
- 检查是否存在非法多边形,如多边形越界,多边形交叉等;
- 对数据集去重或重采样,删除重复数据,降低数据倍增参数;
- 增加数据增强(Data Augmentation)提高多样性;
- 调整权重衰减参数;默认值 0.0001,可调整为 0.01;
下图可以看到,训练 loss 走到第4代之后,就nan了,之后模型无法回归正常。
权重衰减
所有任务权重衰减默认0.0001,通常不需要调整。
-
当权重衰减过大,易导致欠拟合, 模型学不到东西,在训练集和测试集表现都差;
-
当权重衰减过小,易导致过拟合,模型死记硬背训练集,训练集表现优异但测试集表现差。

启用 AMP 混合精度
默认开启。开启后,同时使用 FP32 和 FP16 混合训练,可以减少显存占用并加速训练,几乎无精度损失。

使用OK图训练
当我们做缺陷检测时,经常会遇见过检的情况,也就是将OK图检测为NG。这时就需要告诉模型,哪些是OK,让模型学习OK不应该检出结果。
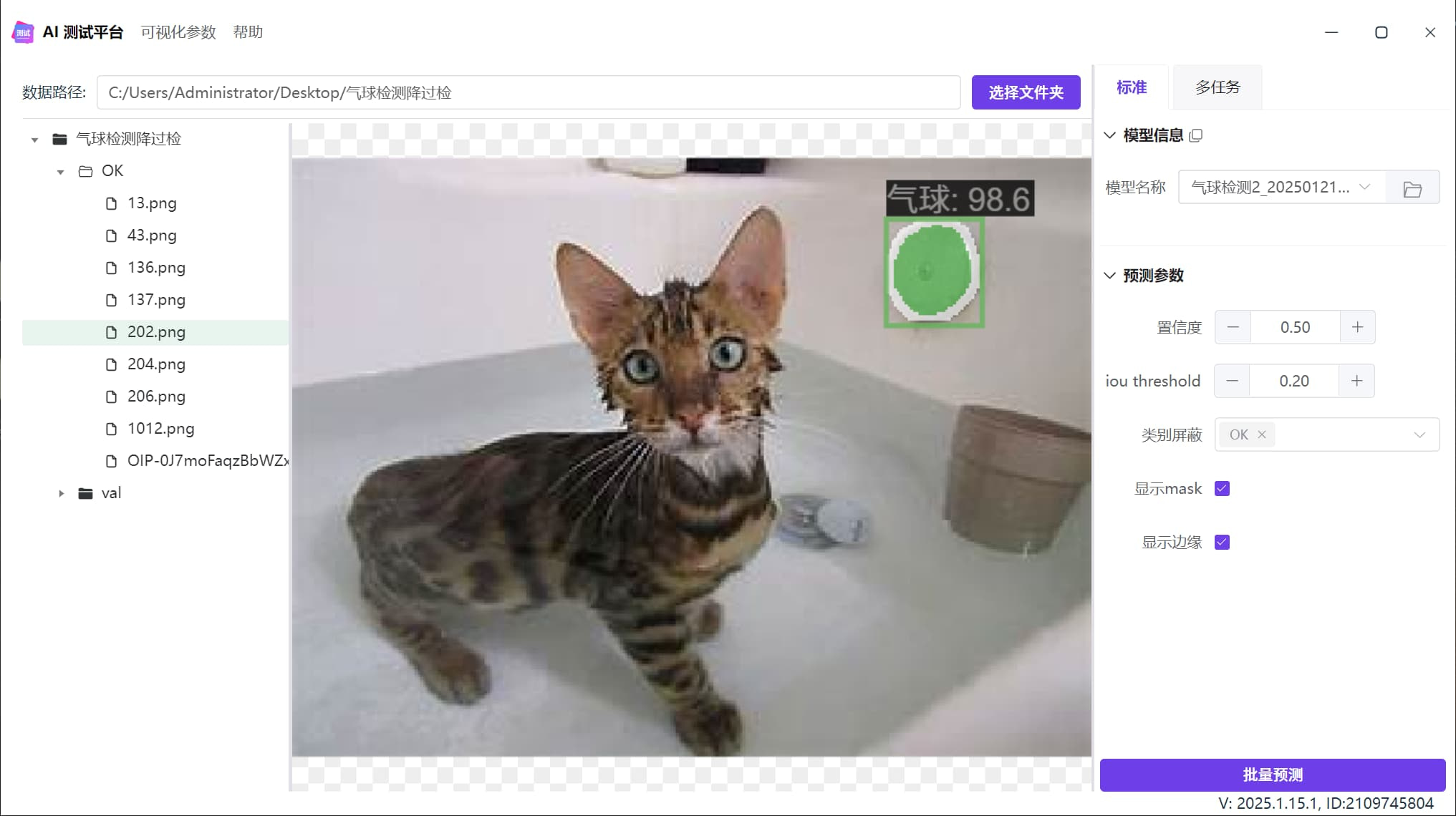
过检现象
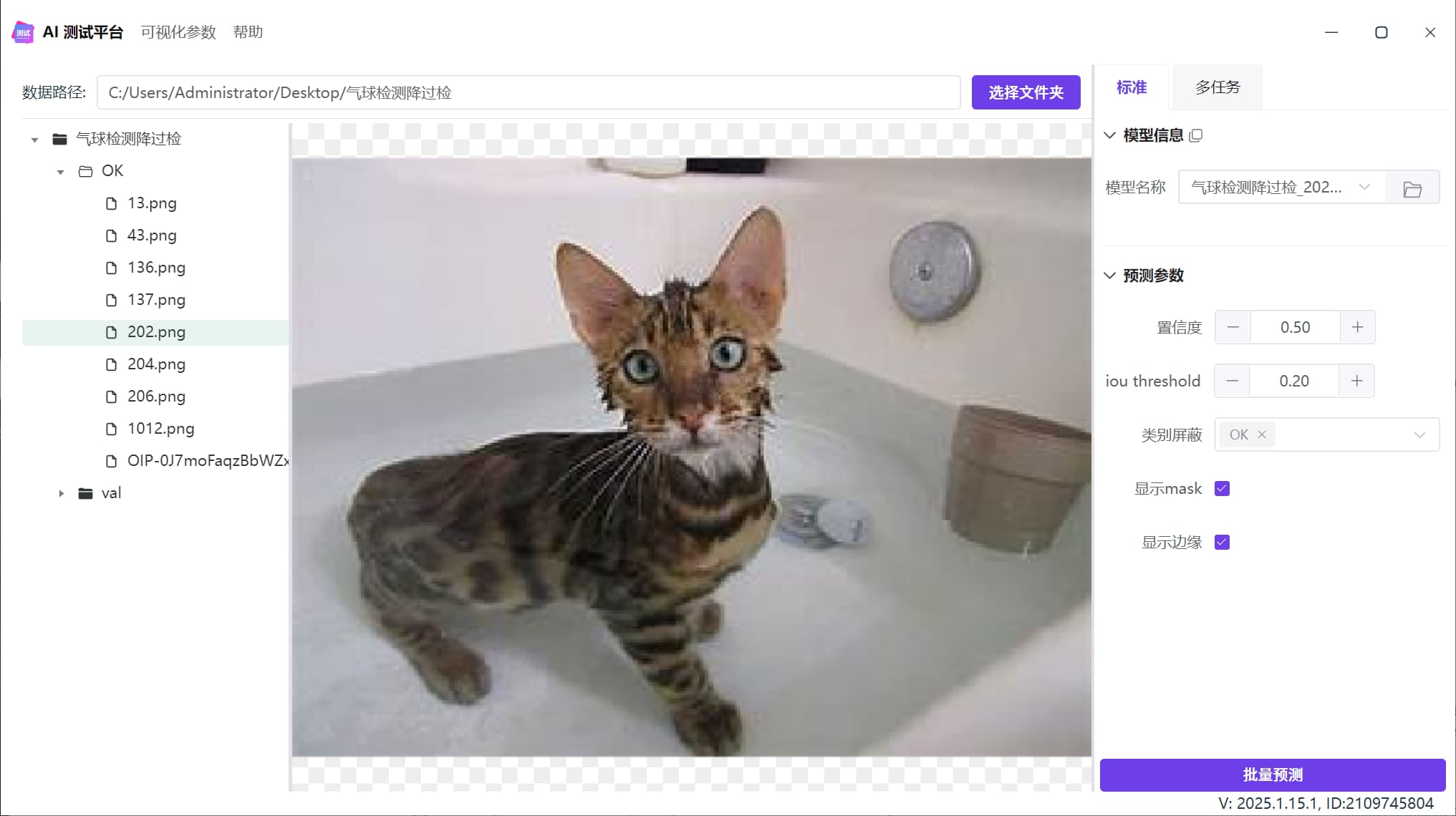
下图是一个气球检测模型,在浴缸内检测到假气球,也就是过检:
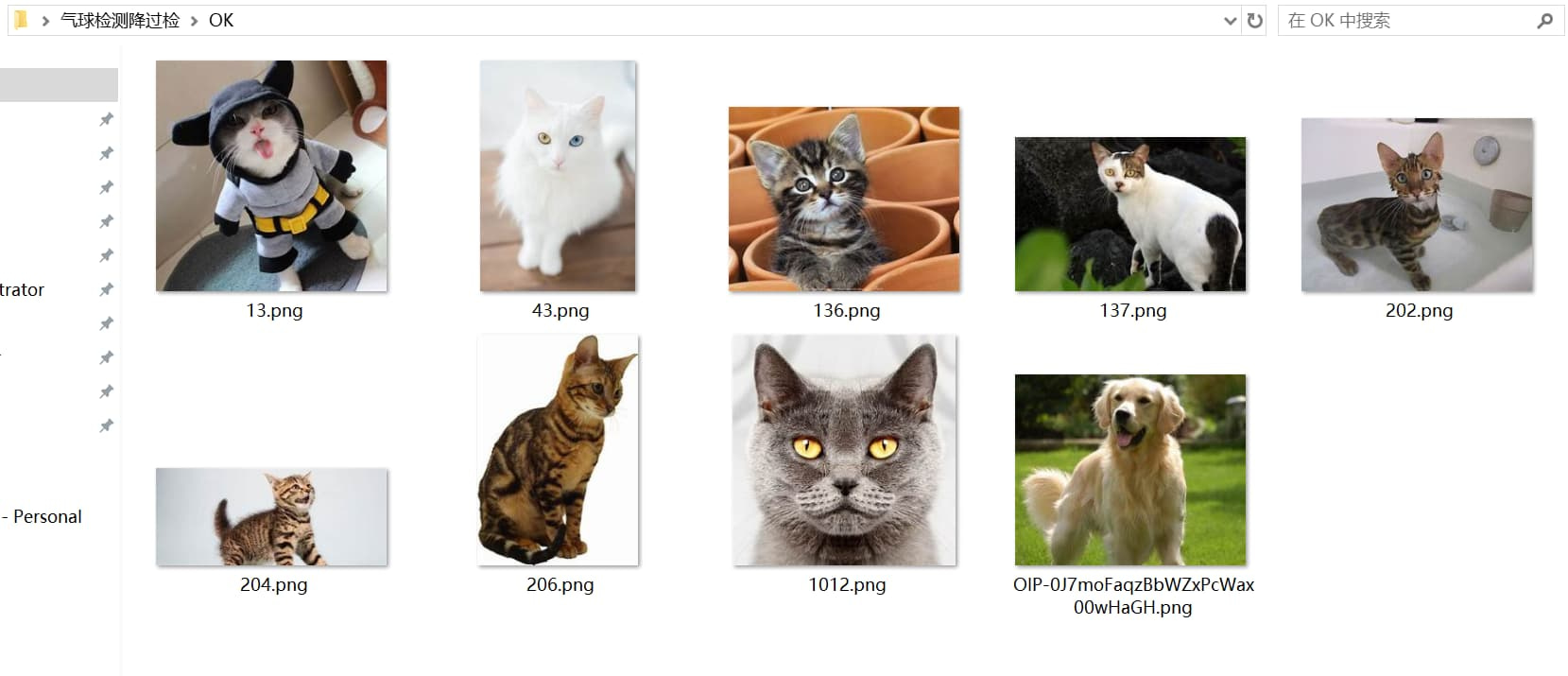
准备OK数据
当需要启动OK图训练时,我们要在数据集根目录内创建名为 OK 的文件夹,并且将过检图片放在这个文件夹内。
注意,不要将任何有目标物体的数据放在这个文件夹中,否则可能会造成漏检问题。
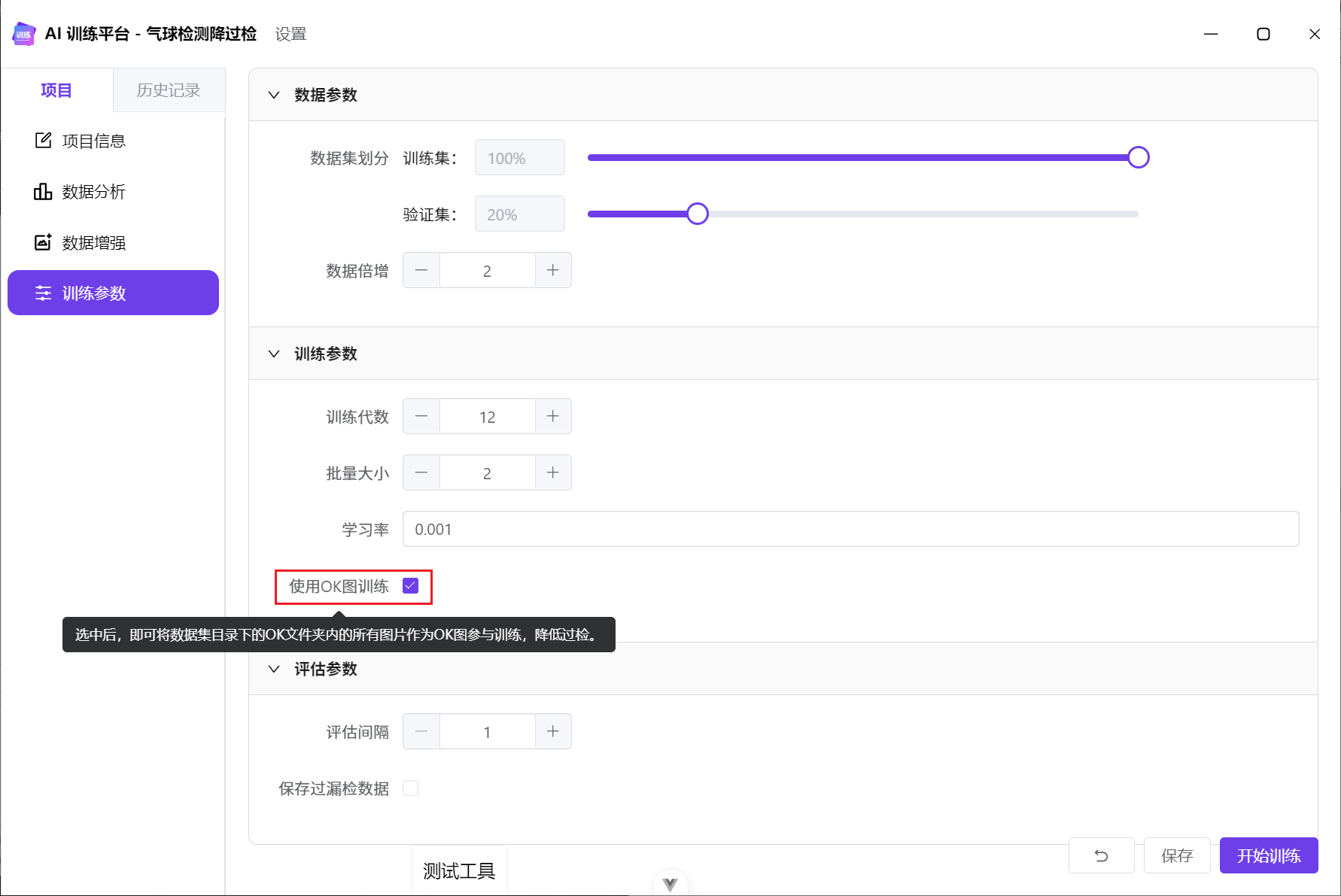
使用OK图训练
在启动训练时,勾选使用OK图训练:
降过检效果
启动降过检之后,模型不会检出气泡: