实例分割
实例分割(Instance Segmentation)模型可以同时识别和分割图像中的每个对象实例。不仅可以标识出对象的类别,并且能精确地分割出每个对象的像素级区域。 在复杂的工业环境中,可以用于检测和分割不同类型的缺陷,例如在一张图中同时检测多个类型的外观缺陷。
应用场景
- 外观缺陷检测
- 产品计数
- 装配检查
文件结构
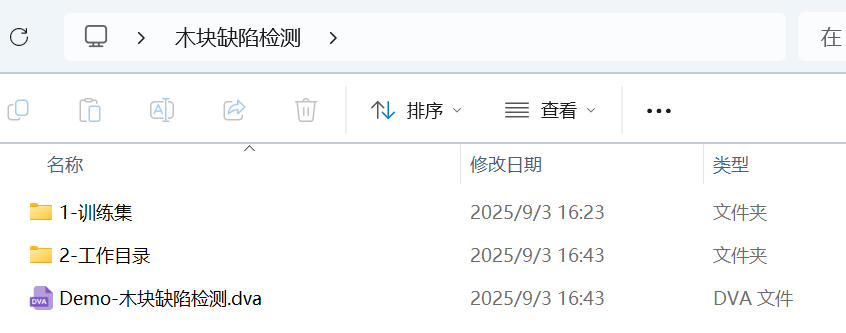
通常,我们将一个任务中的文件存放在一个文件夹下,包含:
- 1-训练集:存放训练数据,内部可以有多层文件夹,用户可根据使用习惯整理数据。
- 2-工作目录:存放训练完成的 AI 模型,日志,中间结果,过漏检数据等。
- AI 项目文件:后缀名为.dva,创建项目后自动生成在训练集同目录下,记录了项目信息和训练参数等。
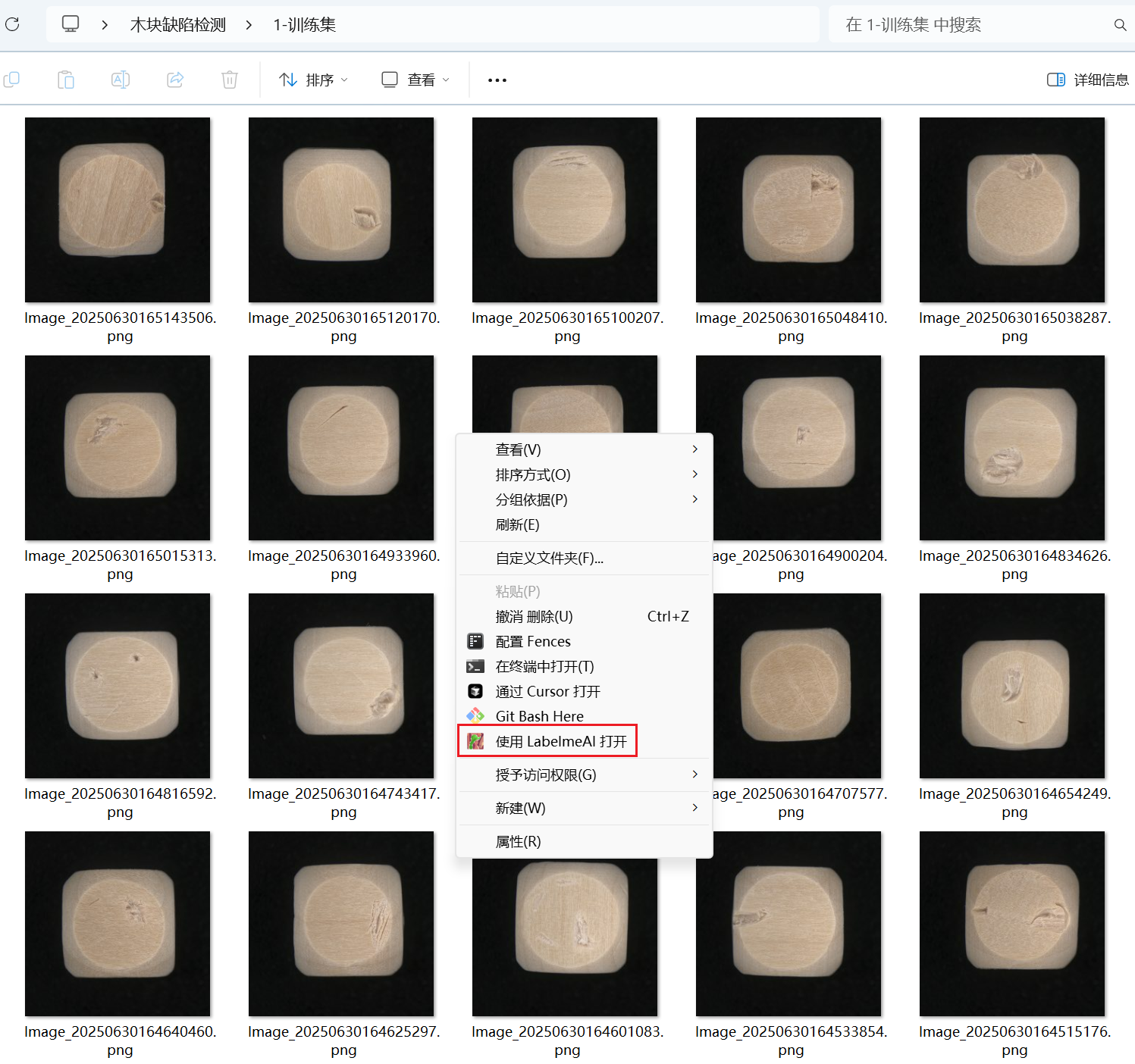
数据集准备
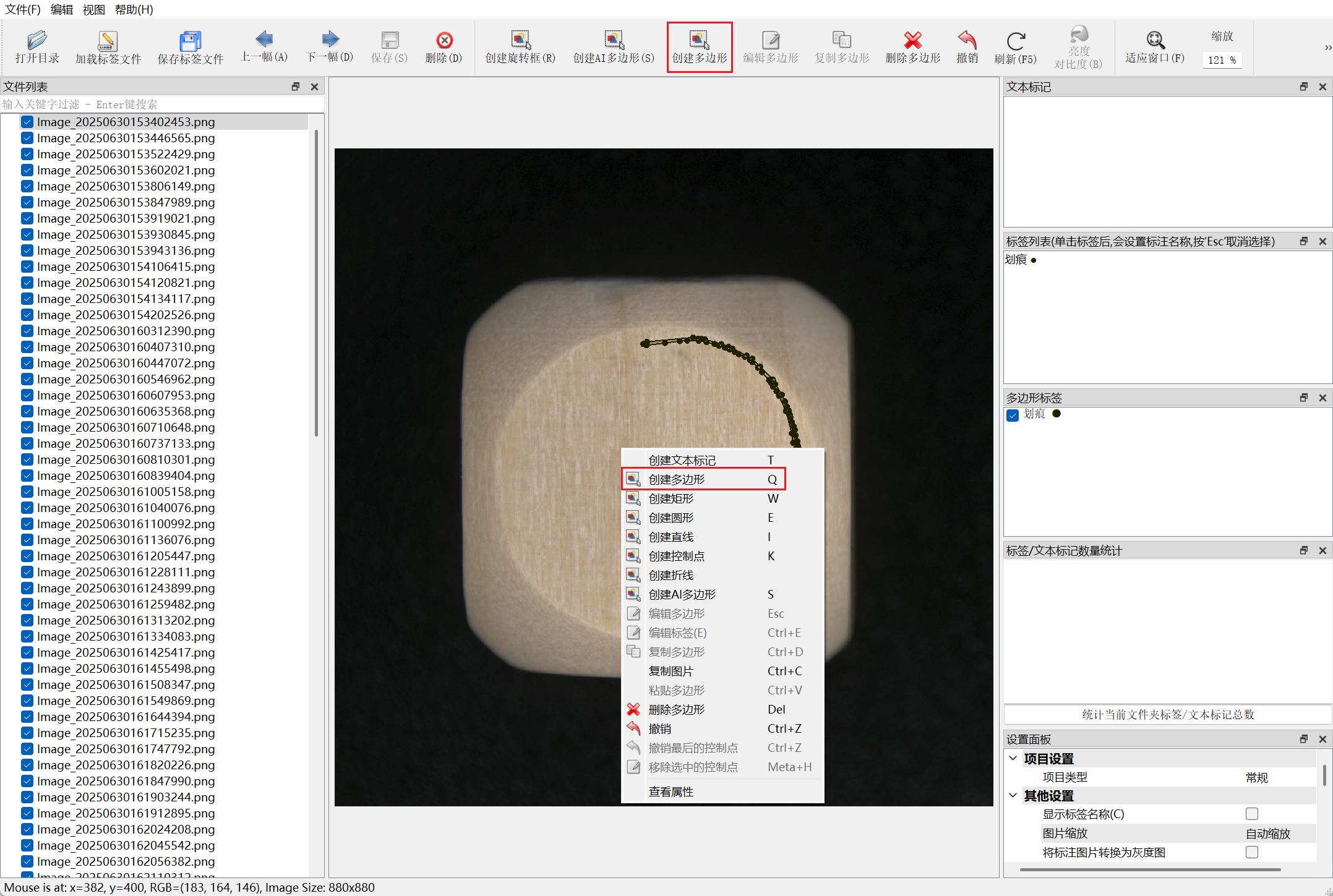
使用 Labelme 标注数据
- 手动标注
- AI 辅助标注:基于大模型的轮廓自动提取,仅需手动选择标签。
- AI 自动标注:支持使用预训练模型或定制化模型批量标注,仅需人工核查。(此功能需要硬件加密锁授权。)
参考:Labelme基本功能
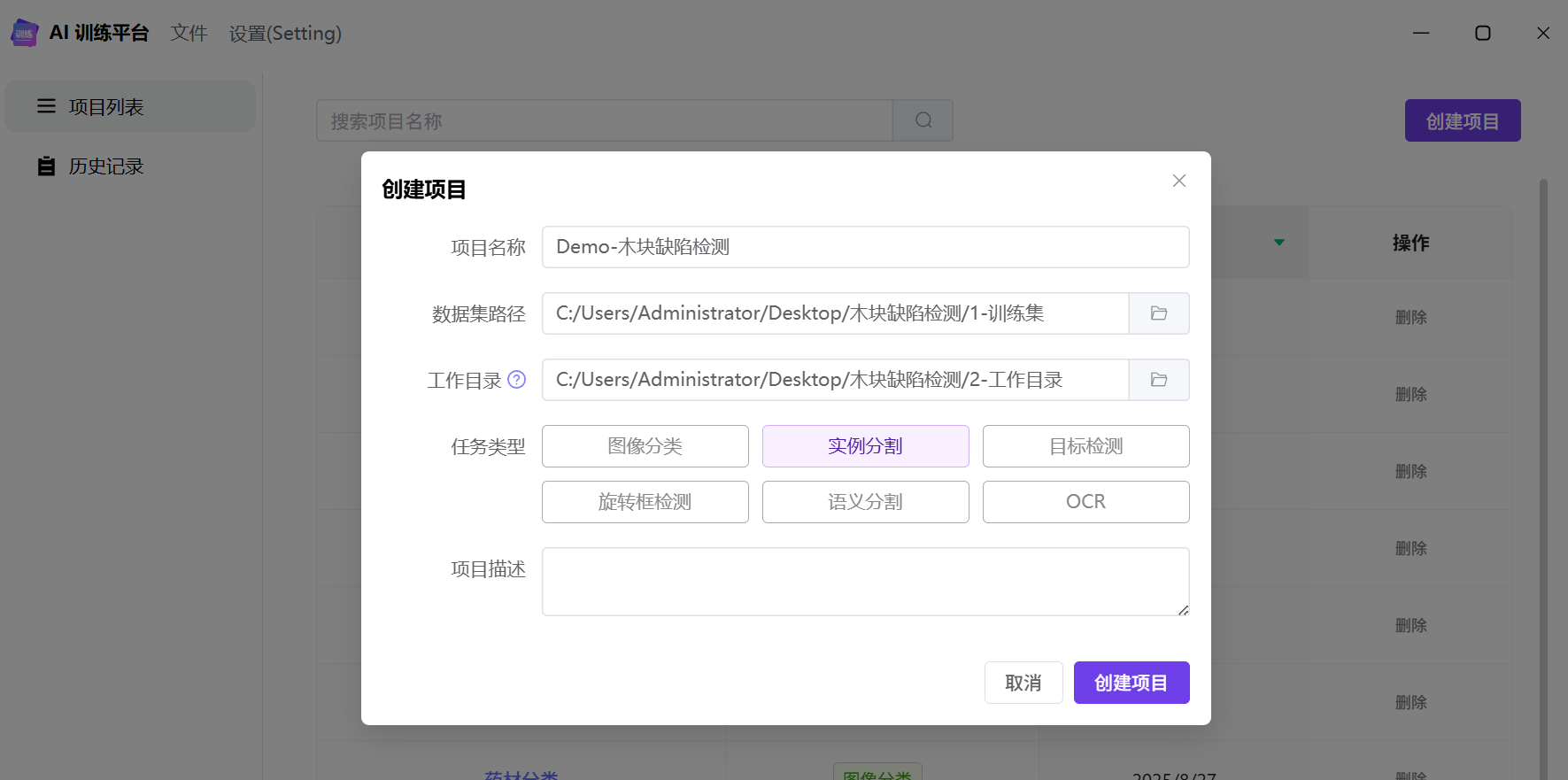
创建项目
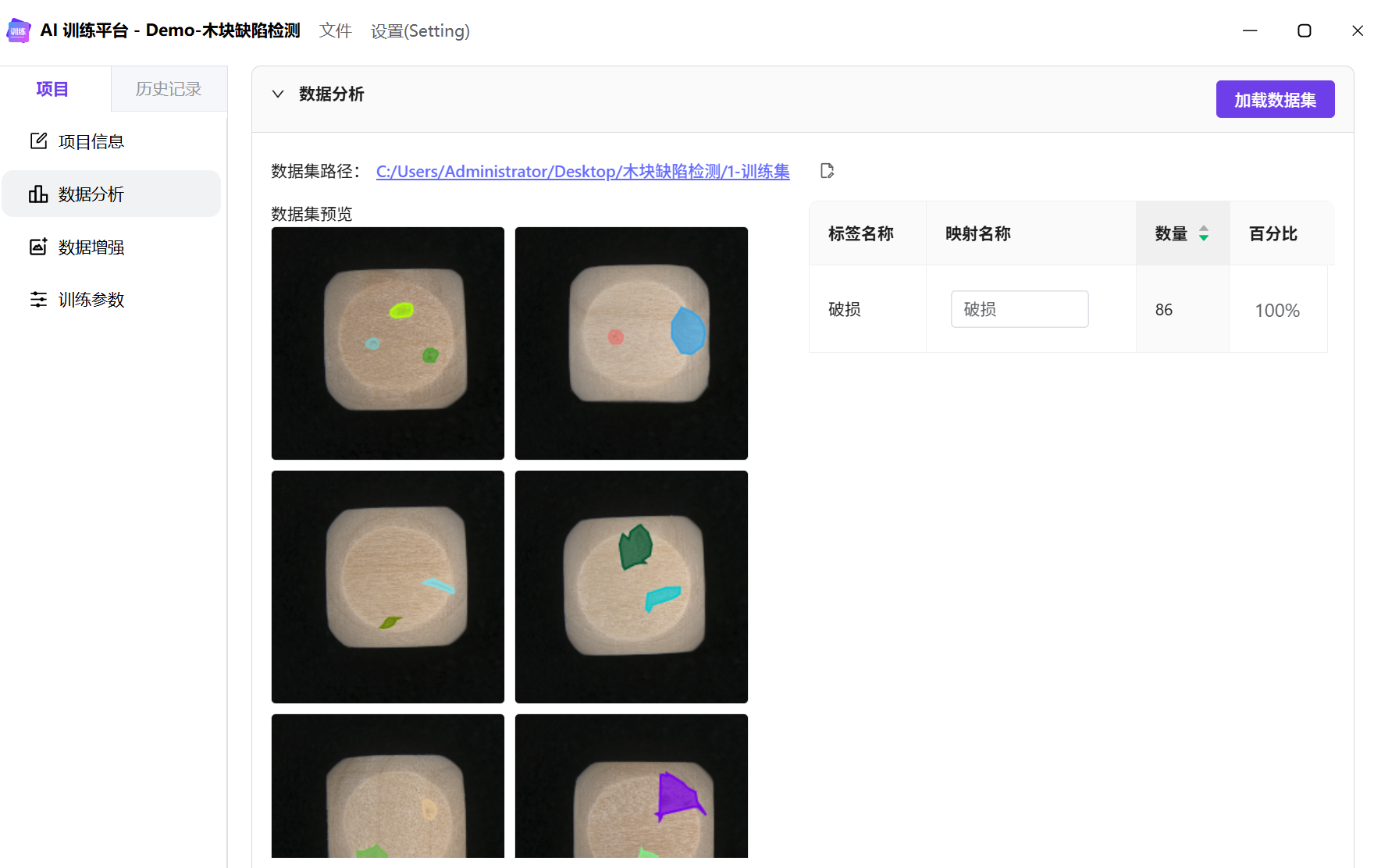
数据集分析
训练集前通过【加载数据集】,查看类别数据量和数据集预览。
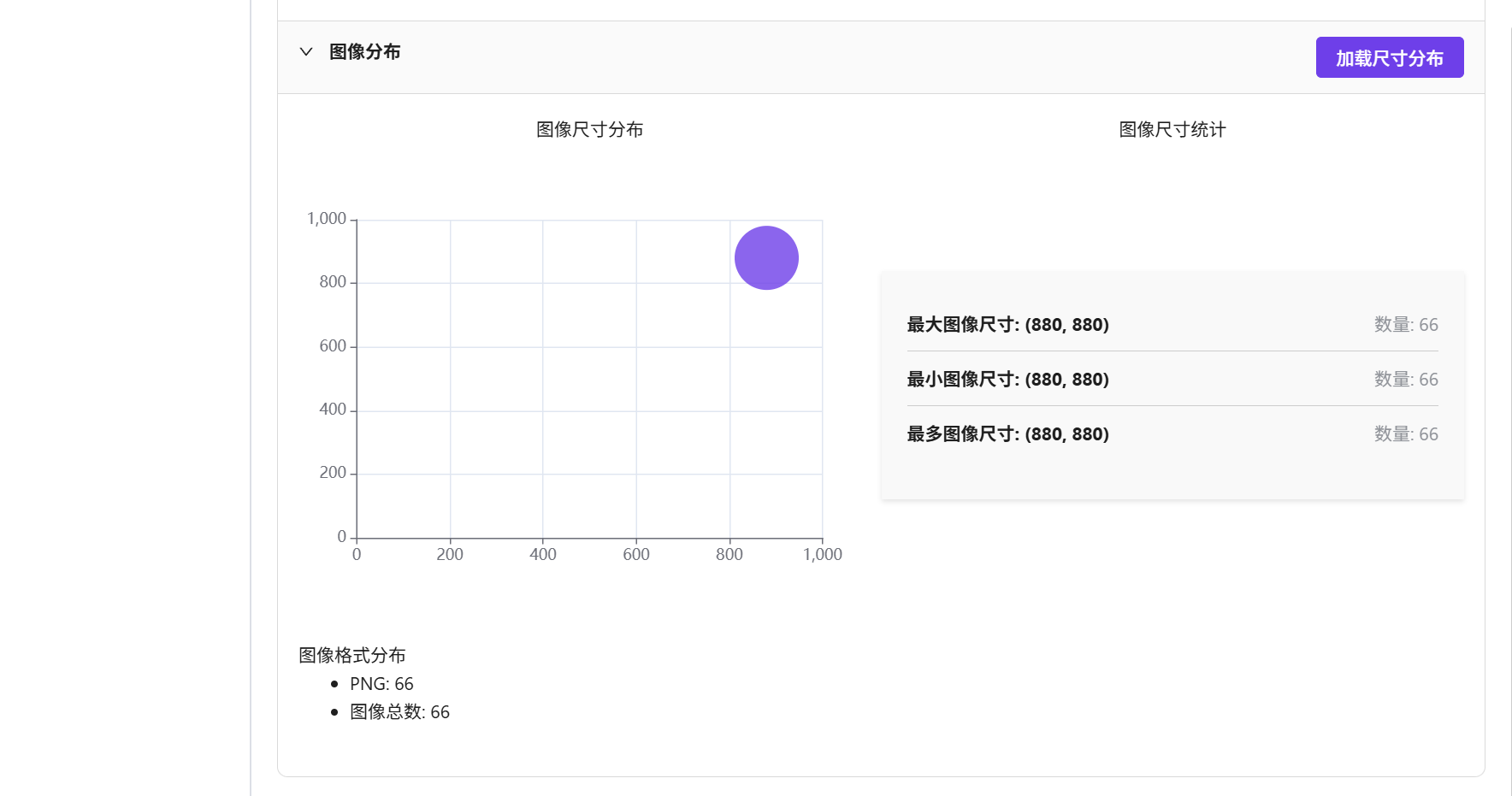
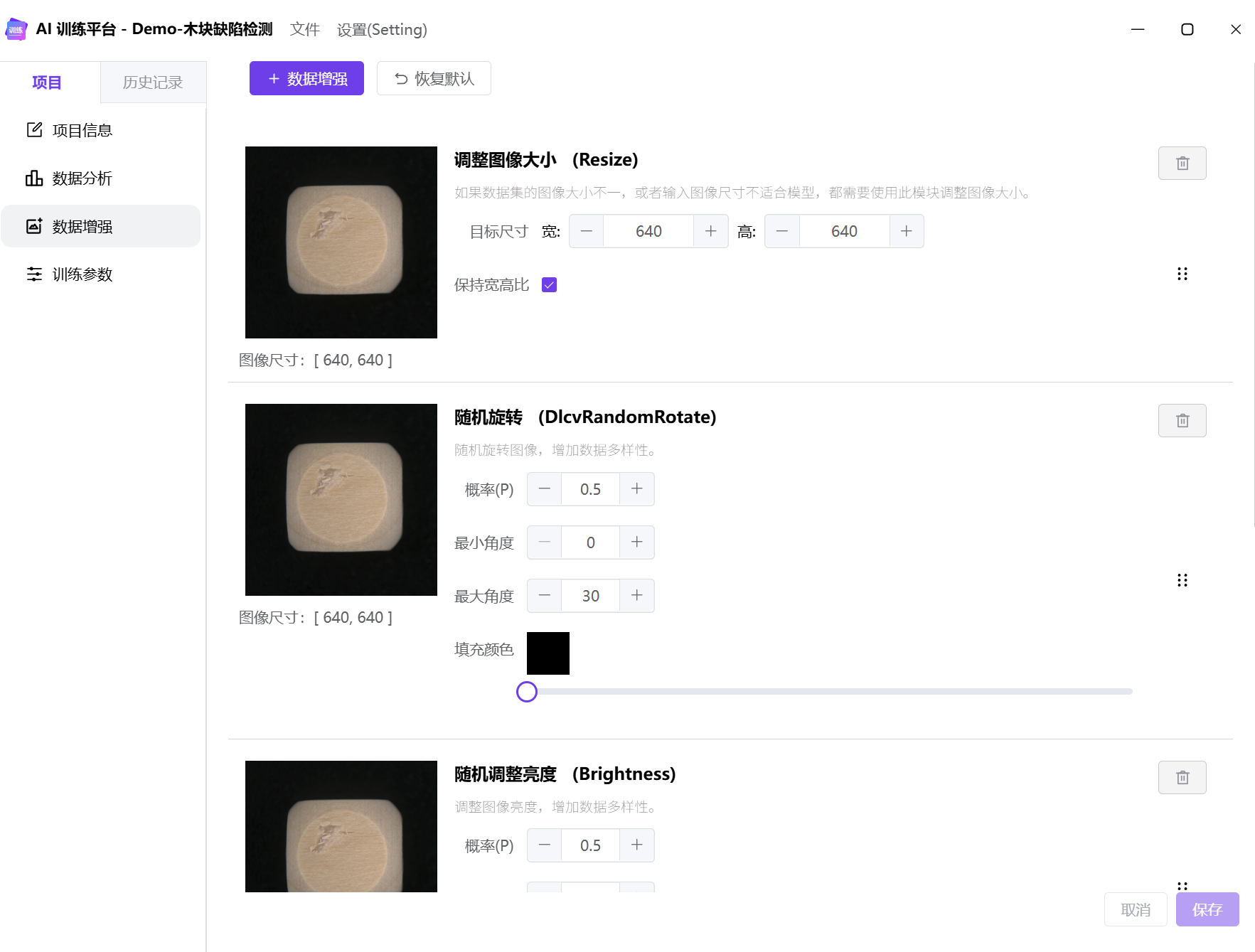
数据增强
训练参数
训练参数的具体介绍可参考:训练参数
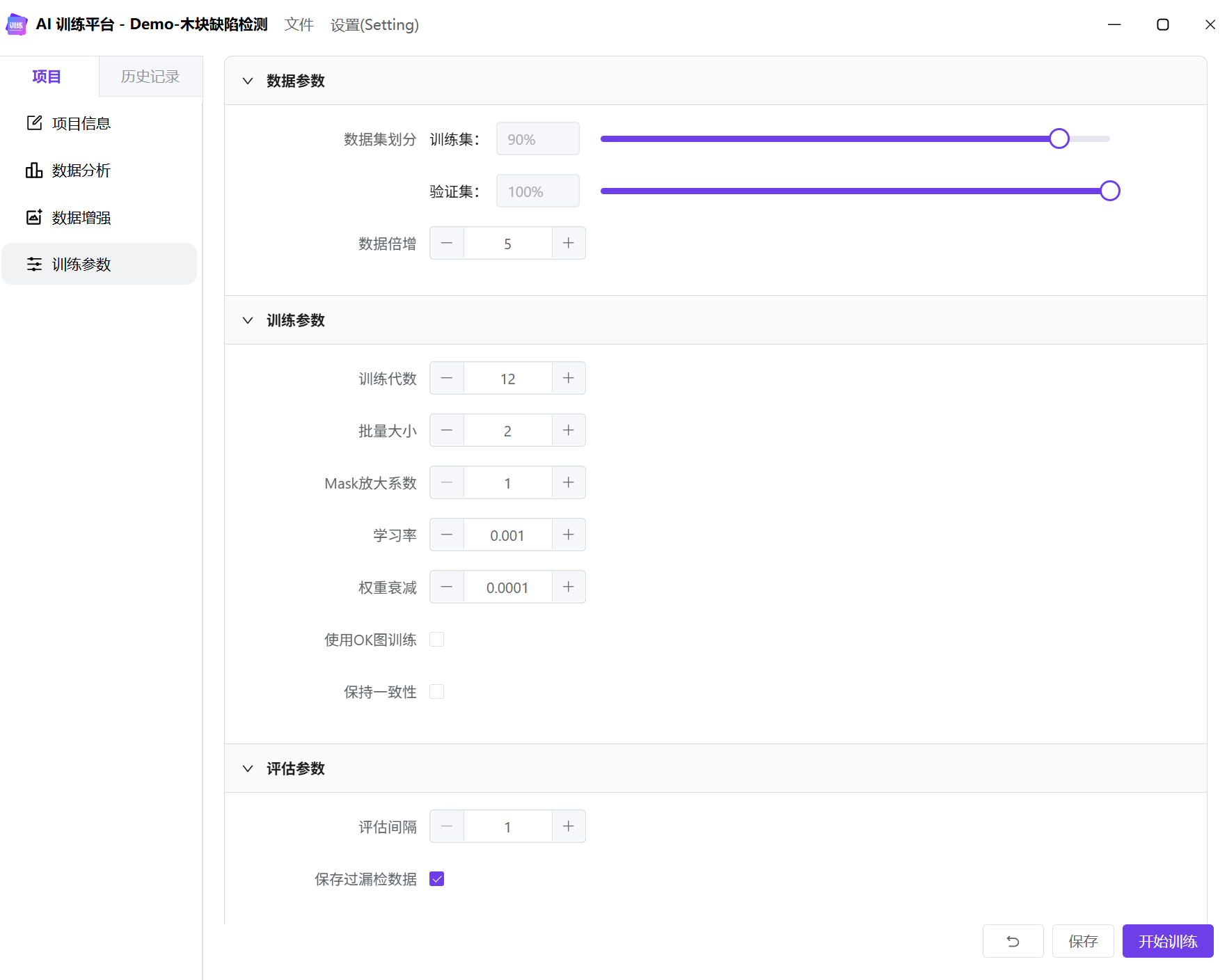
- 学习率:通常使用默认值。Loss 曲线震荡难以收敛时,可以考虑降低学习率,一般降低 10 倍。
- 权重衰减:通常使用默认值,当出现 Loss NaN 的情况时,可以考虑放大权重衰减,放大 10-100 倍。
- 保存过漏检数据:勾选后,训练完成时,会将验证集中的过漏检数据保存在工作目录下。
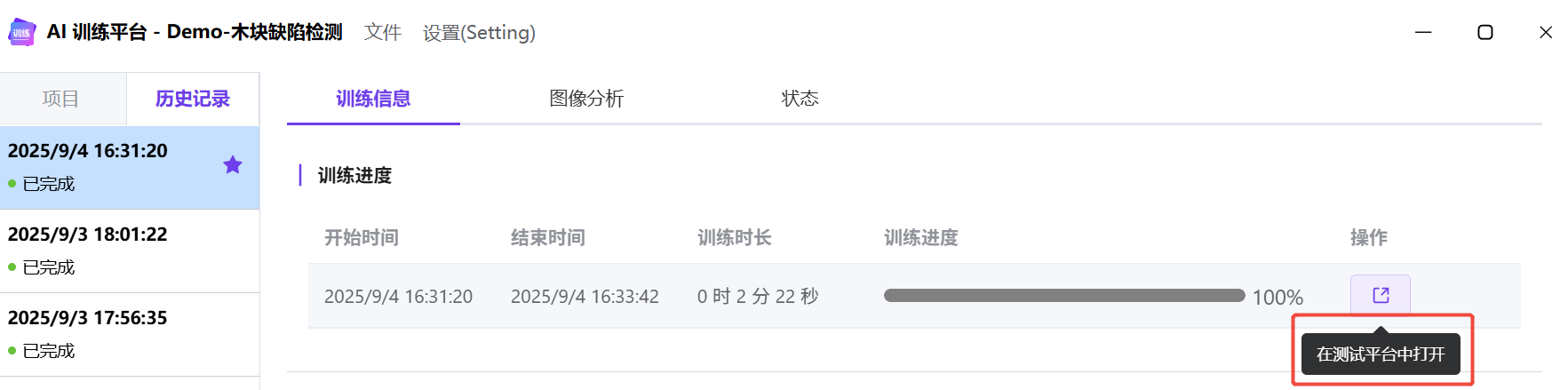
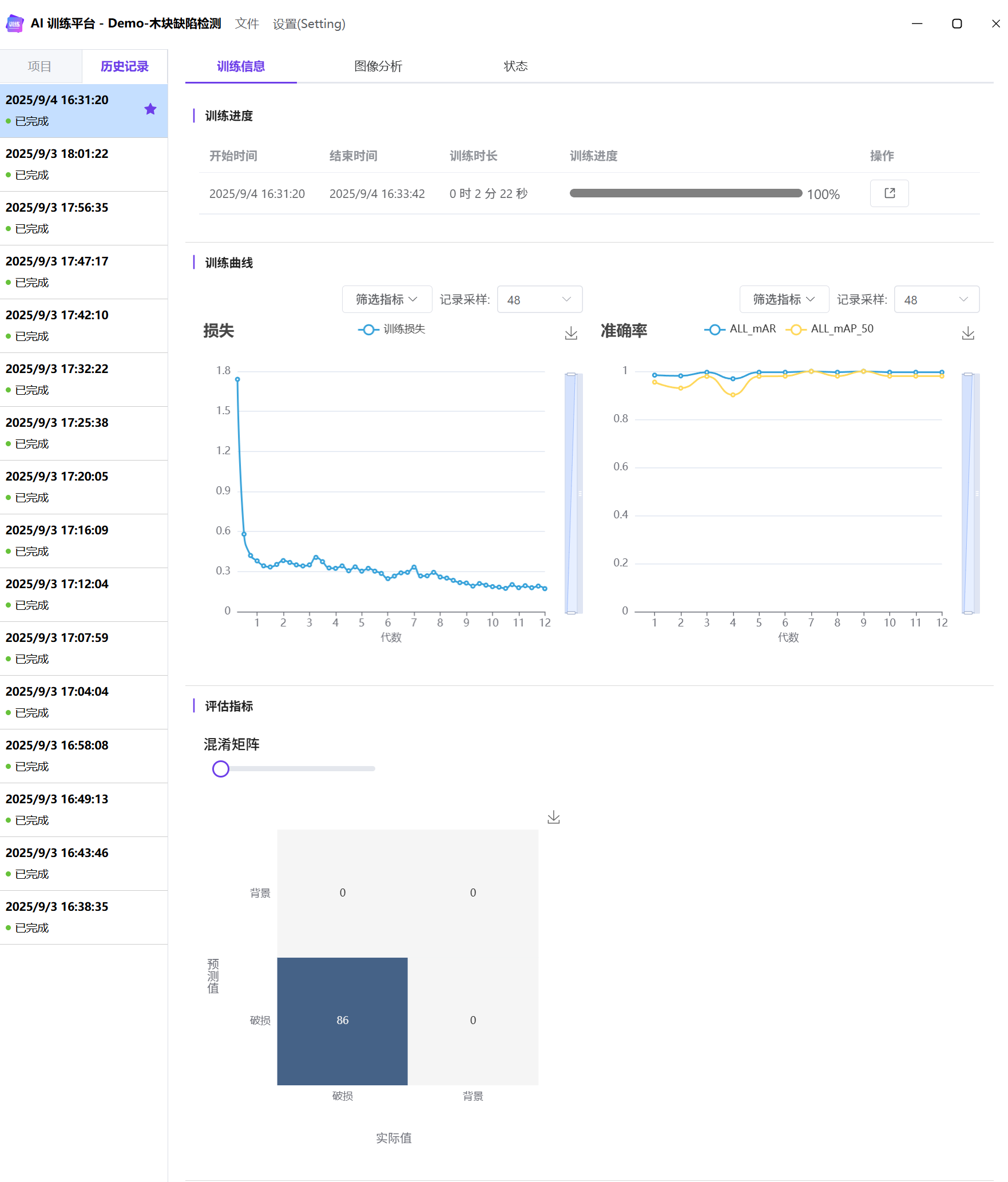
训练记录
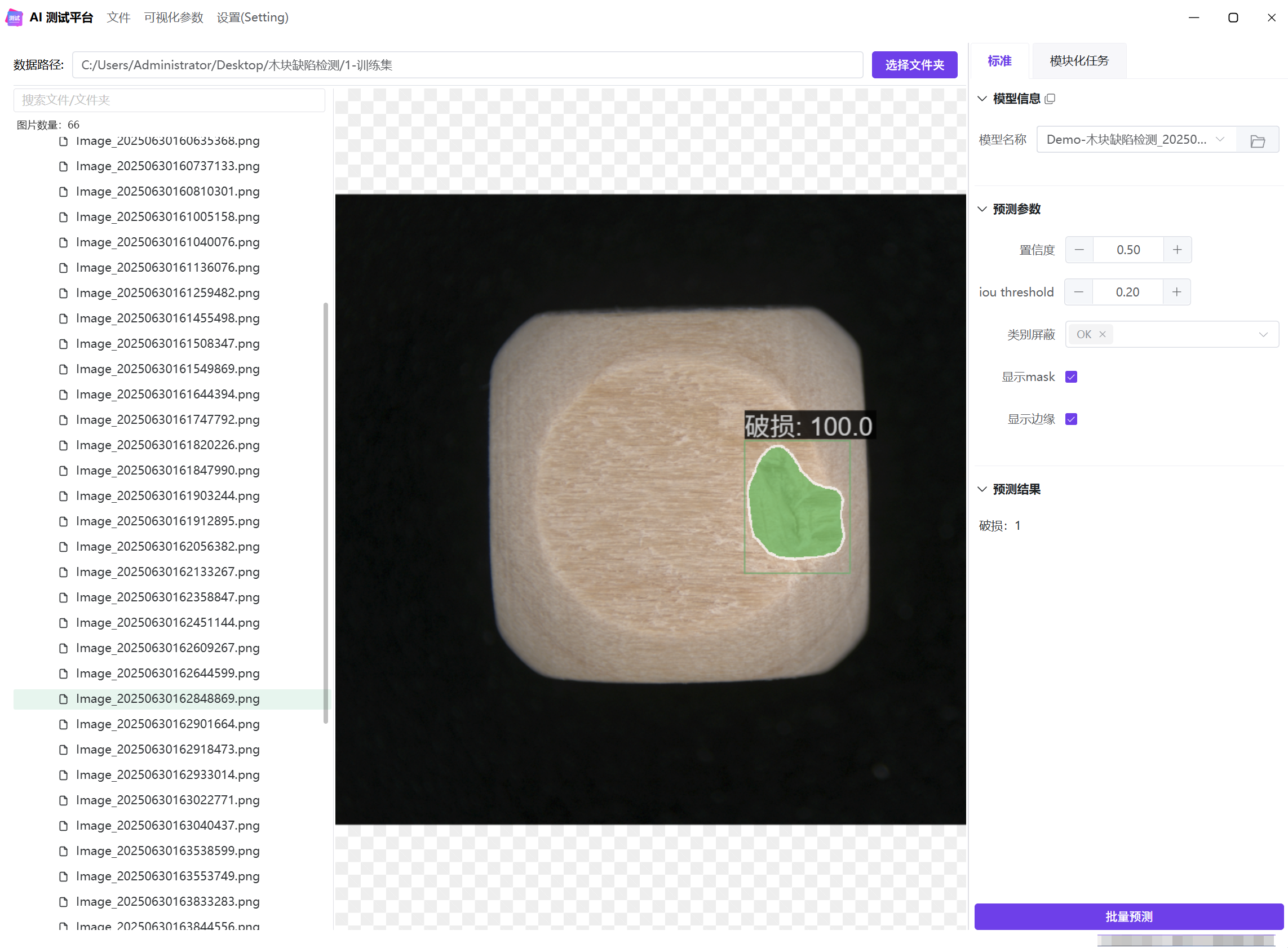
测试模型结果
可以在训练记录中一键跳转到测试平台,会自动加载训练集和 AI 模型;也可以手动打开测试平台,加载需要测试的数据和模型。